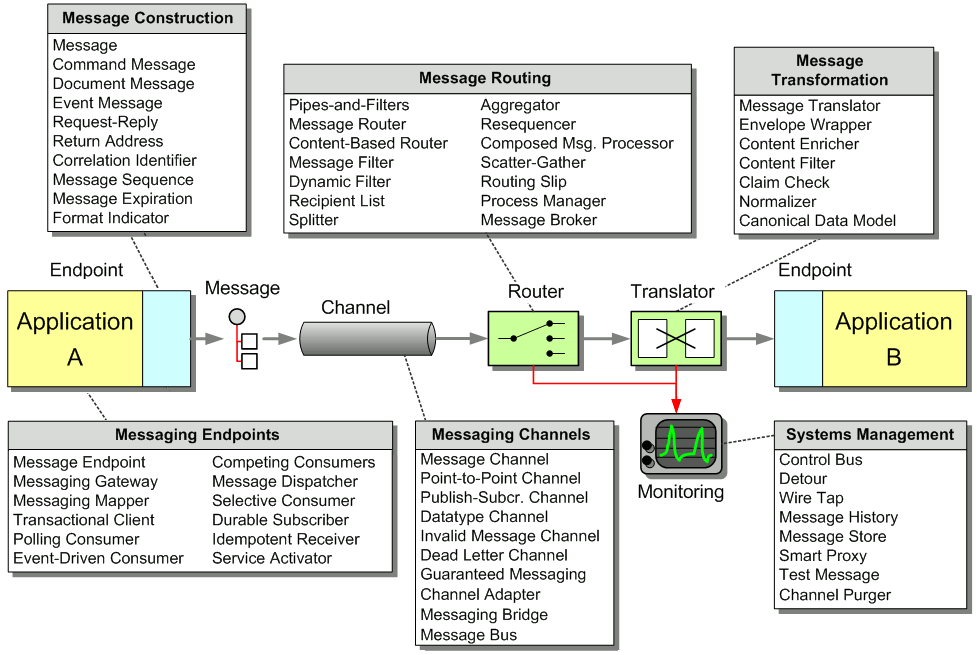
 |
A Splitter is useful to break out a single message into a sequence of sub-messages that can be processed individually. Likewise, a Recipient List or a Publish-Subscribe Channel is useful to forward a request message to multiple recipients in parallel in order to get multiple responses to choose from. In most of these scenarios, the further processing depends on successful processing of the sub-messages. For example, we want to select the best bid from a number of vendor responses or we want to bill the client for an order after all items have been pulled from the warehouse.
How do we combine the results of individual, but related messages so that they can be processed as a whole?
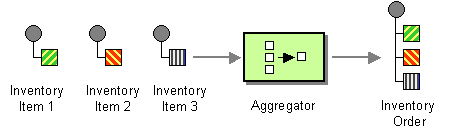
Use a stateful filter, an Aggregator, to collect and store individual messages until a complete set of related messages has been received. Then, the Aggregator publishes a single message distilled from the individual messages.
The Aggregator is a special Filter that receives a stream of messages and identifies messages that are correlated. Once a complete set of messages has been received (more on how to decide when a set is 'complete' below), the Aggregator collects information from each correlated message and publishes a single, aggregated message to the output channel for further processing.
When designing an Aggregator, we need to specify the following items:
- Correlation - which incoming messages belong together?
- Completeness Condition - when are we ready to publish the result message?
- Aggregation Algorithm - how do we combine the received messages into a single result message?
There are a number of strategies for aggregator completeness conditions. The available strategies primarily depend on whether we know how many messages to expect or not. The Aggregator could know the number of sub-messages to expect because it received a copy of the original composite message or because each individual message contains the total count (as described in the Splitter example). Depending on how much the Aggregator knows about the message stream, the most common strategies are as follows:
- "Wait for All" Wait until all responses are received. This scenario is most likely in the order example we discussed earlier. An incomplete order may not be meaningful. So if not all items are received within a certain time-out period an error condition should be raised by the Aggregator. This approach may give us the best basis for decision-making, but may also be the slowest and most brittle (plus we need to know how many messages to expect). A single missing or delayed message will prevent further processing of the whole aggregate. Resolving such error conditions can be a complicated matter in loosely-coupled asynchronous systems because the asynchronous flow of messages makes it hard to reliably detect error conditions (how long should we wait before a message is "missing"?). One way to deal with missing messages is to re-request the message. However, this approach requires the Aggregator to know the source of the message, which may introduce additional dependencies between the Aggregator and other components.
- "Time Out" Wait for a specified length of time for responses and then make a decision by evaluating those responses received within that time limit. If no responses are received, the system may report an exception or retry. This heuristic is useful if incoming responses are scored and only the message (or a small number of messages) with the highest score is used. This approach is common in "bidding" scenarios.
- "First Best" Wait only until the first (fastest) response is received and ignore all other responses. This approach is the fastest, but ignores a lot of information. It may be practical in a bidding or quoting scenario where response time is critical.
- "Time Out with Override" Wait for a specified amount of time or until a message with a preset minimum score has been received. In this scenario, we are willing to abort early if we find a very favorable response; otherwise, we keep on going until time is up. If no clear winner was found at that point, rank ordering among all the messages received so far occurs.
- "External Event" Sometimes the aggregation is concluded by the arrival of an external business event. For example, in the financial industry, the end of the trading day may signal the end of an aggregation of incoming price quotes. Using a fixed timer for such an event reduces flexibility because it does not other variability. Also, a designated business even in form of an Event Message allows for central control of the system. The Aggregator can listen for the Event Message on a special control channel or receive a specially formatted message that indicates the end of the aggregation.
... Read the entire pattern in the book Enterprise Integration Patterns
Example: Serverless Loan Broker on AWSNEW
The modern implementation of the Loan Broker using AWS serverless constructs includes an implementation of a Aggregator with Lambda and DynamoDB. The Aggregator uses a simple completeness condition of waiting for a minimum number of answers. The surrounding workflow, implemented using AWS Step Functions, adds a time-out component.
Example: Serverless Loan Broker on GCPNEW
The modern implementation of the Loan Broker using GCP includes an implementation of a Aggregator with a Cloud Function and Datastore. The implementation stores all elements of a specific Aggregate under the same key and can therefore fail when inserting the record (Datastore doesn't seem to like heavy contention on one record). It therefore configures retry logic on the incoming messages. The Aggregator signals back to the Process Manager on completion.
Related patterns:
Scatter-Gather, Introduction to Composed Messaging Examples, Content-Based Router, Control Bus, Correlation Identifier, Composed Message Processor, Event-Driven Consumer, Event Message, Guaranteed Delivery, Message Expiration, Point-to-Point Channel, Process Manager, Publish-Subscribe Channel, Recipient List, Resequencer, Splitter, Transactional Client
Integration Pattern Language