(By Jonathan Simon)
It is easy to distance yourself from a large collection of patterns or a pattern language. Patterns are the abstraction of an idea in a reusable form. Often, the very generic nature of patterns that makes them so useful also makes them hard to grasp. Sometimes the best thing to help understand patterns is a real world example. Not a contrived scenario of what could happen; but what actually happens and what will happen.
This chapter applies patterns to solve problems using a discovery process. The system we will discuss is a bond trading system that I worked with for two years from initial design through production. We will explore scenarios and problems that were encountered and how to solve them with patterns. This involves the decision process of choosing a pattern, as well as how to combine and adjust patterns to suit the needs of the system. And this is all done taking into account the forces encountered in real systems including business requirements, client decisions, architectural and technical requirements, as well as legacy system integration. The intent of this approach is to provide a clearer understanding of the patterns themselves through practical application.
Building a System
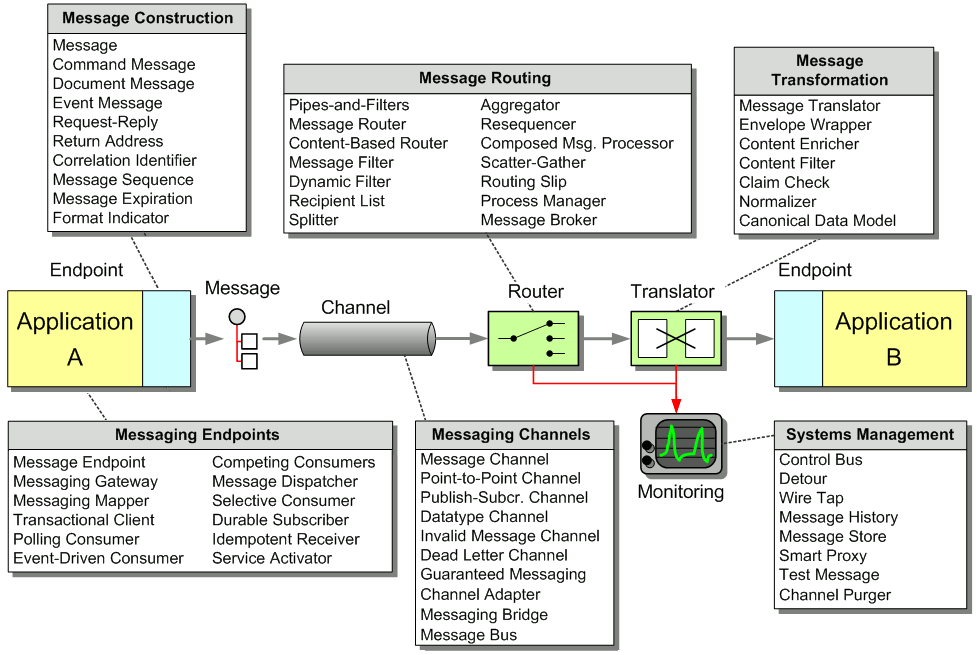
A major Wall Street investment bank sets out to build a bond pricing system in an effort to streamline the workflow of their bond trading desk. Currently, bond traders have to send prices for a large number of bonds to several different trading venues, each with its own user interface. The goal for the system is to minimize the minutiae of pricing all of their bonds combined with advanced analytic functionality specific to the bond market in a single encapsulated user interface. This means integration and communication with several components over various communication protocols. The high level flow of the system looks like this:
High Level Flow
First, market data comes into the system. Market data is data regarding the price and other properties of the bond representing what people are willing to buy and sell the bond for on the free market. The market data is immediately sent to the analytics engine that alters the data. Analytics refers to mathematical functions for financial applications that alter the prices and other attributes of bonds. These are generic functions that use input variables to tailor the results of the function to a particular bond. The client application that will run on each trader desktop will configure the analytics engine on a per trader basis, controlling the specifics of the analytics for each bond the trader is pricing. Once the analytics are applied to the market data, the modified data is sent out to various trading venues where traders from other firms can buy or sell the bonds.
Architecture with Patterns
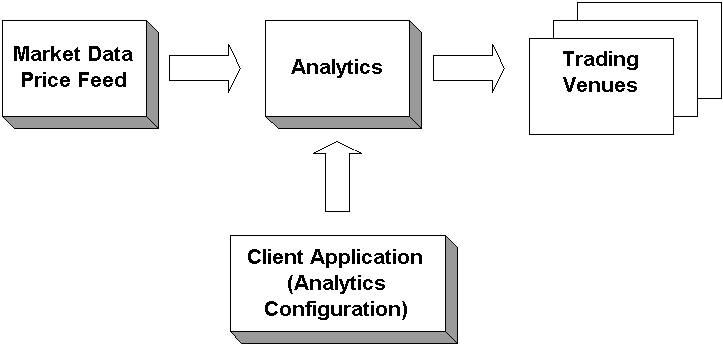
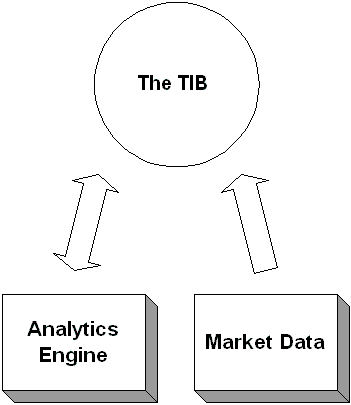
With this overview of the workflow of the system, we can approach some of the architectural problems we encounter during the design process. Let’s take a look at what we know to date. Traders need a very responsive application on both Windows NT and Solaris workstations. Therefore, we decided to implement the client application as a Java thick client because of its platform independence and its ability to quickly respond to user input and market data. On the server side, we are inheriting legacy C++ components that our system will utilize. The market data components communicate with the TIBCO Information Bus (TIB) messaging infrastructure.
We are inheriting the following components:
- Market Data Price Feed Server: Publishes incoming market data to the TIB.
- Analytics Engine: Performs analytics on incoming market data and broadcasts the modified market data to the TIB.
- Contribution Server: Performs all communication with trading venues. The trading venues are third party components not controlled by the bank.
Legacy Market Data Subsystem
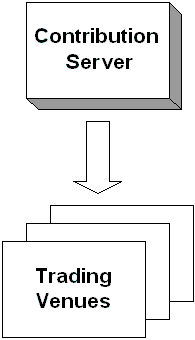
Legacy Contribution Subsystem
We need to decide how the separate subsystems (Java thick client, market data, and contribution) are going to communicate. We could have the thick client communicate directly with the legacy servers, but that would require too much business logic on the client. Instead, we’ll build a pair of Java gateways to communicate with the legacy servers—The Pricing Gateway for market data a Contribution Gateway for sending prices to trading venues. This will achieve nice encapsulation of the business logic related to these areas. The current components in the system are shown below. The connections marked as “???” indicate that we are still unsure how some of the components will communicate.
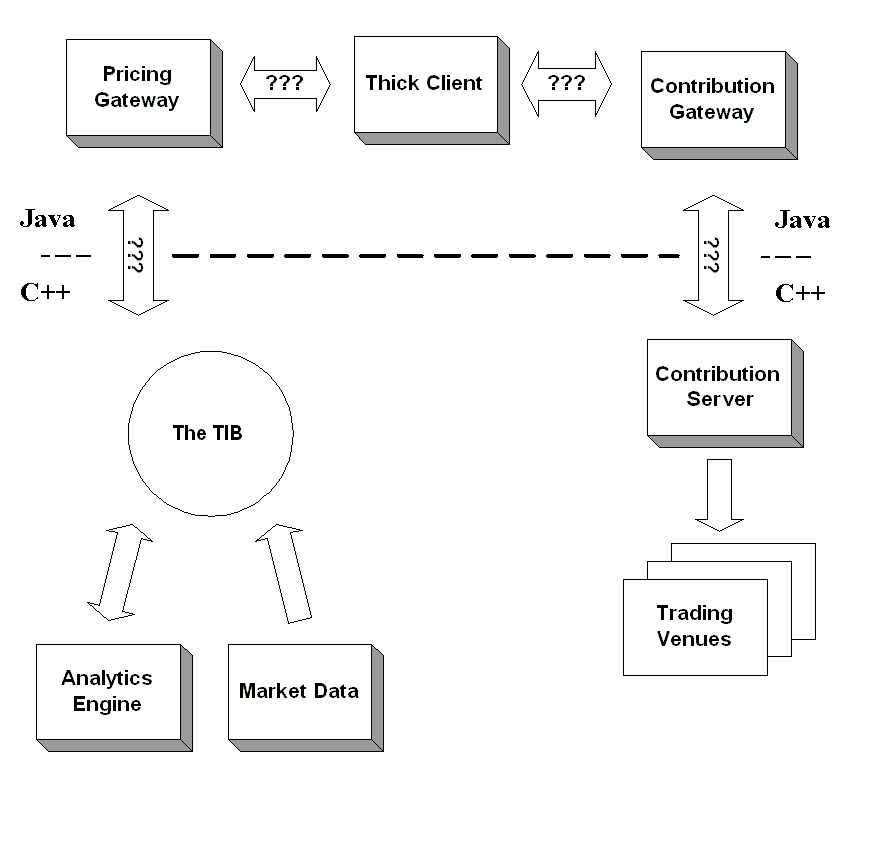
The system and its components
The first communication question is how to integrate the Java thick client and the two Java server components in order to exchange data. Let’s look at the four integration styles suggested in this book: File Transfer, Shared Database, Remote Procedure Invocation, and Messaging. We can rule out Shared Database immediately because we wanted to create a layer of abstraction between the client and the database and don’t want to have database access code in the client. File Transfer can similarly be ruled out since minimal latency is required to ensure current prices are sent out to the trading venues. This leaves us with a choice between Remote Procedure Invocation or Messaging.
The Java platform provides built-in support for both Remote Procedure Invocation and Messaging. RPC-style integration can be achieved using Remote Method Invocation (RMI), CORBA, or Enterprise Java Beans (EJB). The Java Messaging Service (JMS) is the common API for messaging-style integration. So both integration styles are easy to implement in Java.
So which will work better for this project, Remote Procedure Invocation or Messaging? There’s only one instance of the Pricing Gateway and one instance of the Contribution Gateway in the system, but usually many Thick Clients simultaneously connect to these services (one for each bond trader that happens to be logged in at a particular time). Furthermore, the bank would like this to be a generic pricing system that can be utilized in other applications. So besides an unknown number of Think Clients, there may be an unknown number of other applications using the pricing data coming out of the Gateways.
A Thick Client (or other application using the pricing data) can fairly easily use RPC to make calls to the Gateways to get pricing data and invoke processing. However, pricing data will constantly be published, and certain clients are only interested in certain data, so getting the relevant data to the proper clients in a timely manner could be difficult. The clients could poll the Gateways, but that will create a lot of overhead. It would be better for the Gateways to make the data available to the clients as soon as it is available. This, however, will require each Gateway to keep track of which clients are currently active, and which want what particular data; then, when a new piece of data becomes available (which will happen numerous times per second), the Gateway will have to make an RPC to each interested client to pass the data to the client. Ideally, all clients should be notified simultaneously, so each RPC needs to be made in its own concurrent thread. This can work, but is getting very complicated very fast.
Messaging greatly simplifies this problem. With Messaging, we can define separate channels for the different types of pricing data. Then, when a Gateway gets a new piece of data, it will add a message containing that data to the Publish-Subscribe Channel for that data type. Meanwhile, all clients interested in a certain type of data will listen on the channel for that type. In this way, the Gateways can easily send out new data to whomever is interested, without needing to know how many listener applications there are or what they are.
The clients still need to be able to invoke behavior in the Gateways as well. Since there are ever only two Gateways, and the client can probably block while the method is invoked synchronously, these client-to-Gateway invocations can fairly easily be implemented using RPC. However, since we are already using messaging for Gateway-to-client communication, messages are probably just as good a way to implement client-to-Gateway communication as well.
Therefore, all communication between the Gateways and the clients will be accomplished through messaging. Because all of the components are written in Java, JMS presents an easy choice for as the messaging system. This is effectively creating a Message Bus or an architecture that will make it possible for future systems to integrate with the current system with little or no changes to the messaging infrastructure. This way, the business functionality of the application can be easily used by other application the bank develops.
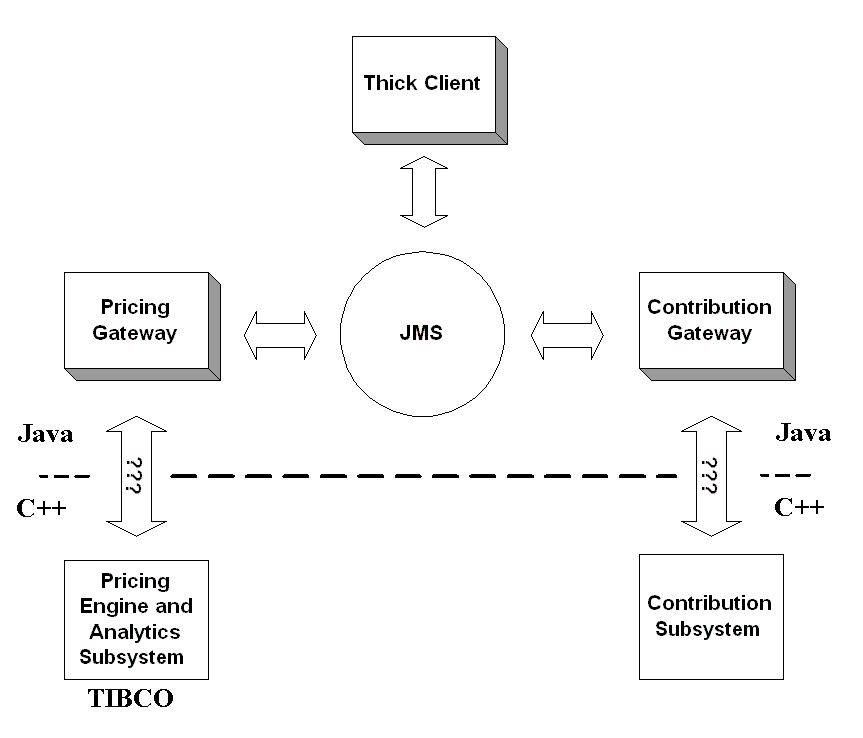
Java Components Communicating with JMS
JMS is simply a specification and we need to decide on a JMS-compliant messaging system. We decided to use IBM MQSeries JMS because the bank is an “IBM shop,” using WebSphere application servers and many other IBM products. As a result, we will use MQSeries since we already have a support infrastructure in place and a site license of the product.
The next question is how to connect the MQSeries messaging system with the standalone C++ Contribution server and the TIBCO based Market Data and Analytics Engine servers. We need a way for the MQSeries consumers to have access to the TIB messages. But how? Perhaps we could use the Message Translator pattern to translate TIB messages into MQSeries messages. Although the C++ client for MQSeries serves as a Message Translator, using it would sacrifice JMS server independence. And although TIBCO does have a Java API, the customer architect and manager have rejected it. As a result, the Message Translator approach has to be abandoned.
The bridge from the TIB server to the MQSeries server requires communication between C++ and Java. We could use CORBA, but then what about the messaging? A closer look at the Message Translator pattern shows it is related to the Channel Adapter in its use of communication protocols. The heart of a Channel Adapter is to connect non-messaging systems to messaging systems. A pair of channel adapters that connects two messaging systems is a Messaging Bridge.
The purpose of a Messaging Bridge is to transfer messages from one messaging system to another. This is exactly what we are doing with the added complexity of the intra-language Java to C++ communication. We can implement the cross language Messaging Bridge using a combination of Channel Adapters and CORBA. We will build two lightweight Channel Adapter servers, one in C++ managing communication with the TIB, and one in Java managing communication with JMS. These two Channel Adapter, which are Message Endpoints themselves, will communicate with each other via CORBA. Like our choice for MQSeries, we will use CORBA rather than JNI since it is a company standard. The messaging bridge implements the effectively simulated message translation between seemingly incompatible messaging systems and different languages.
Message Translator using Channel Adapters
The next diagram shows the current system design including the Gateways and other components. This is a good example of pattern application. We combined two Channel Adapters with a non-messaging protocol to implement the Message Translator pattern, effectively using one pattern to implement another pattern. Additionally, we changed the Channel Adapters' context to link two messaging systems with a non-messaging cross language translation protocol rather than connecting a messaging system to a non-messaging system.
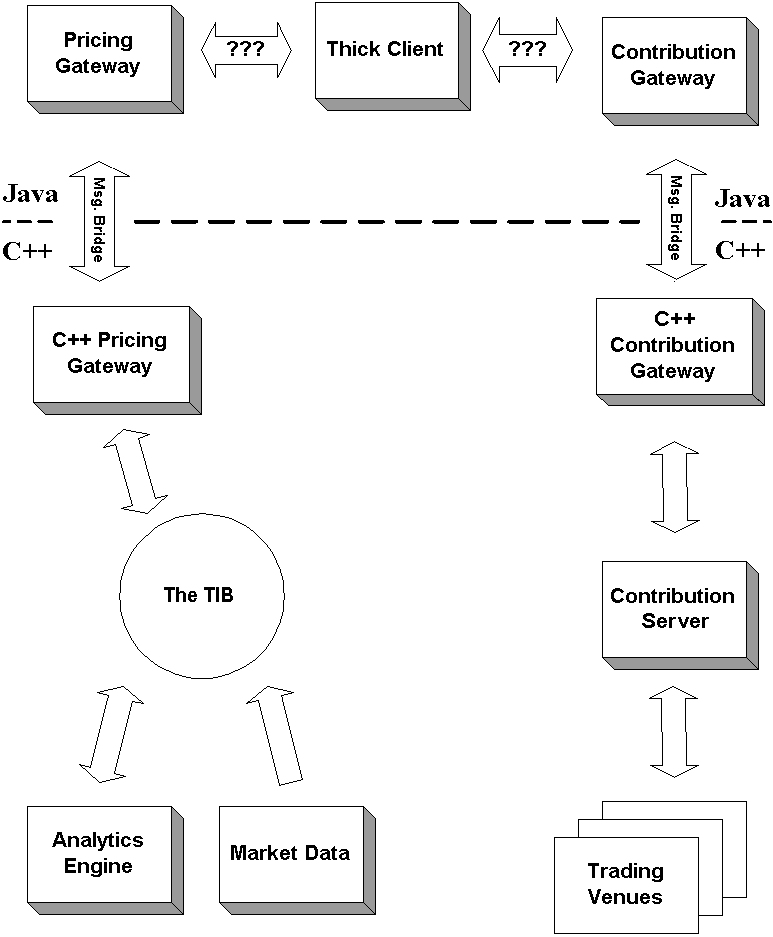
The current system with the Channel Adapters
Structuring Channels
A key to working with patterns is not only knowing when to use which pattern, but also how to most effectively use it. Each pattern implementation has to take into account specifics of the technology platform as well as other design criteria. This section applies the same discovery process to find the most efficient use of the Publish-Subscribe Channel in the context of the market data server communicating with the analytics engine.
Real time market data originates with market data feed, a C++ server that broadcasts market data on the TIB. The market data feed uses a separate Publish-Subscribe Channel for each bond it is publishing prices for. This may seem a little extreme since each new bond needs its own new channel. But this is not so severe since you do not actually need to create channels in TIBCO. Rather, channels are referenced by a hierarchical set of topic names called subjects. The TIBCO server then filters a single message flow by subject, sending each unique subject to a single virtual channel. The result of which is a very lightweight message channel.
We could create a system that publishes on a few channels and subscribers could listen only for prices they are interested in. This would require subscribers to use a Message Filter or Selective Consumer to filter the entire data flow for interesting bond prices, deciding whether each message should be processed as it is received. Given that the market data is published on bond-dedicated channels, subscribers can register for updates on a series of bonds. This effectively allows subscribers to "filter" by selectively subscribing to channels and only receiving updates of interest rather than deciding after the message is received. It is important to note that using multiple channels to avoid filtering is a nonstandard use of messaging channels. In context of the TIBCO technology however, we are really deciding whether to implement or own filters or utilize the channel filtering built into TIBCO -- rather than whether to use so many channels.
The next component we need to design is the analytics engine, another C++/TIB server that will modify the market data and rebroadcast it to the TIB. Although it is out of the scope of our Java/JMS development, we are working closely with the C++ team to design it since we are the analytics engine's primary 'customer'. The problem at hand is to find the channel structure that most efficiently rebroadcast the newly modified market data.
Since we already have one dedicated Message Channel per bond inherited from the market data price feed, it would be logical to modify the market data and rebroadcast the modified market data on the bond dedicated Message Channel. But this will not work since the analytics modifying the bonds prices are trader specific. If we rebroadcast the modified data on the bond Message Channel, we will destroy the data integrity by replacing generic market data with trader specific data. On the other hand, we could have a different message type for trader specific market data that we publish on the same channel allowing subscribers to decide which message they are interested in to avoid destroying the data integrity. But then clients will have to implement their own filters to separate out messages for other traders. Additionally, there will a substantial increase in messages received by subscribers, placing an unnecessary burden on them.
There are two options:
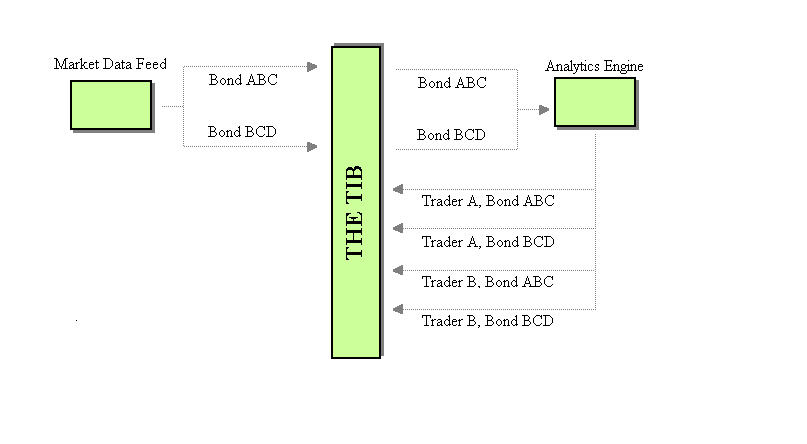
- One Channel per Trader: Each trader has a designated channel for the modified market data. This way, the original market data remains intact and each trader application can listen to its specific traders Message Channel for the modified price updates.
- One Channel per trader per Bond: Create one Message Channel per-trader per-bond solely for the modified market data of that bond. For example, the market data for bond ABC would be published on channel "Bond ABC" while the modified market data for trader A would be published on Message Channel "Trader A, Bond ABC", modified market data for trader B on "Trader B, Bond ABC," and so on.
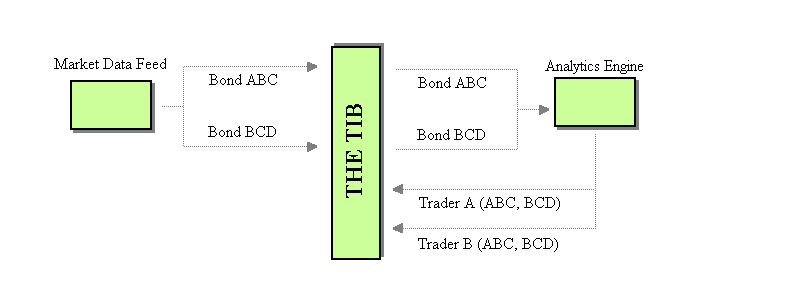
One channel per trader
One channel per bond per trader
There are advantages and disadvantages to each approach. The per-bond approach, for example, uses a lot more Message Channel. In the worst-case scenario, the number of Message Channel will be the number of bonds total multiplied by the number of traders. We can put upper bounds on the number of channels that will be created since we know that there are only around 20 traders and they never price more than a couple hundred bonds. This puts the upper limit below the 10,000 range, which is not so outlandish compared to the nearly 100,000 Message Channel the market data price feed is using. Also, since we are using the TIB and Message Channel are quite inexpensive, the number of Message Channels is not a severe issue. On the other hand, the sheer number of Message Channels could be a problem from a management perspective. Every time a bond is added a channel for each trader must be maintained. This could be severe in a very dynamic system. Our system, however, is essentially static. It also has an infrastructure for automatically managing Message Channels. This combined with the inherited architecture of a legacy component using a similar approach minimizes the downside. This is not to say we should make an unnecessarily excessive number of Message Channels. Rather, we can implement an architectural approach that uses a large number of Message Channels when there is a reason.
And there is a reason in this case that comes down to the location of logic. If we implement the per trader approach, the Analytics Engine needs logic to group input and output channels. This is because the input channels from the Analytics Engine are per bond and the output Message Channels would be per trader, requiring the Analytics Engine to route all analytics input from multiple bonds for a particular trader to a trader specific output Message Channel. This effectively turns the analytics engine into a Content-Based Router to implement custom routing logic for our application.
Following the Message Bus structure, the Analytics Engine is a generic server that could be used by several other systems in the. So we don’t want to cloud it with system specific functionality. On the other hand, the per-bond approach works since the idea of a trader owning the analytics output of bond prices is a company accepted practice. The per-bond approach keeps the Message Channel separation of the market data feed intact, while adding several more Message Channels. Before we reach the client, we want a Content-Based Router to combine these several channels into a manageable number of channels. We don’t want the client application running on the trader’s desktop to be listening to thousands or tens of thousands of Message Channels. Now the question becomes where to put the Content-Based Router. We could simply have the C++/TIB Channel Adapter forward all of the messages to the Pricing Gateway on a single Message Channel. This is bad for two reasons; we would be splitting up the business logic between C++ and Java, and we would lose the benefit of the separate Message Channels on the TIB side allowing us to avoid filtering later in the data flow. Looking at our Java components, we could either place it in the Pricing Gateway or create an intermediary component between the Pricing Gateway and the client.
In theory, if we persisted the bond-based separation of Message Channels all the way to the client, the Pricing Gateway would rebroadcast pricing information with the same channel structure as the Pricing Gateway and Analytics Engine. This means a duplication of all of the bond dedicated TIB channels in JMS. Even if we create an intermediary component between the Pricing Gateway and the client, the Pricing Gateway will still have to duplicate all of the channels in JMS. On the other hand, implementing logic directly in the Pricing Gateway allows us to avoid duplicating the large number of channels in JMS—allowing us to create a much smaller number of channels in the order of one per trader. The Pricing Gateway registers itself through the C++/TIB Channel Adapter as a consumer for each bond of every trader in the system. Then the Pricing Gateway will forward each specific client only the messages related to that particular trader. This way, we only use a small number of Message Channels on the JMS end, while maximizing the benefit of the separation on the TIB end.
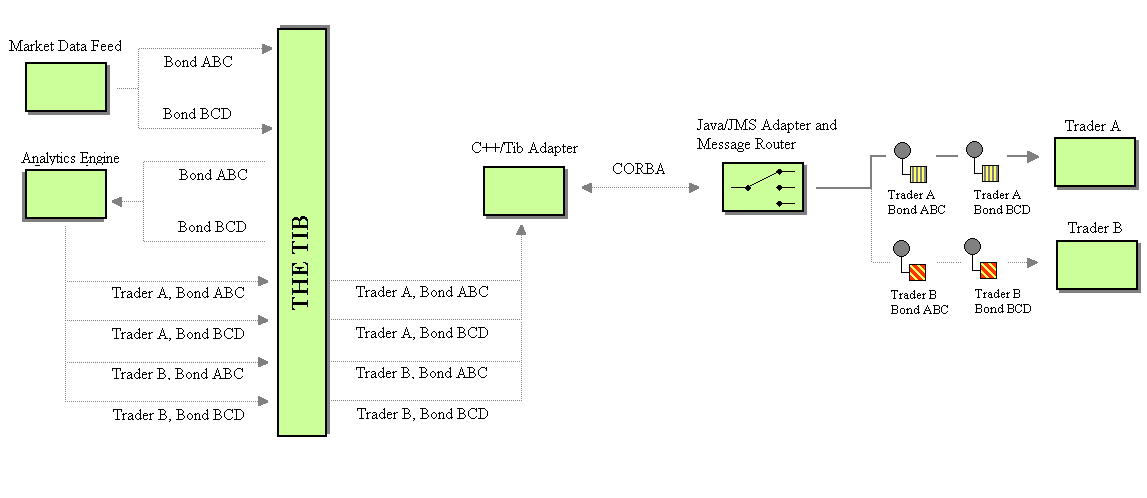
The complete Market Data Flow to the client
The Message Channel layout discussion is a good example of how integrating patterns is important. The goal here was to figure out how to effectively use the Message Channels. Saying you use a pattern isn’t enough. You need to figure out how to best implement it and incorporate into your system to solve the problems at hand. Additionally, this example shows business forces in action. If we could implement business logic in any of our components, we could have gone with the per trader approach and implemented an overall more simple approach with many less channels.
Selecting a Message Channel?
Now that we know the mechanics of the communication between the Java/JMS components and the C++/ TIBCO components, and we have seen some Message Channel structuring, we need to decide which type of JMS Message Channels the Java components should use to communicate. Before we can choose between the different Message Channels available in JMS, let’s look at the high level message flow of the system. We have two gateways (Pricing and Contribution) communicating with the client. Market data flows to the client from the Pricing Gateway which sends it out to the Contribution Gateway. The client application sends message to the Pricing Gateway to alter the analytics being applied to each bond. The Contribution Gateway also sends messages to the Client application relaying the status of the price updates to the different trading venues.

The system message flow
The JMS specification describes two Message Channel types, Point-to-Point Channel (JMS Queue) and Publish-Subscribe Channel (JMS Topic). Recall that the case for using publish-subscribe is to enable all interested consumers to receive a message while the case for using point-to-point is to ensure that only one eligible consumer receives a particular message.
Many systems would simply broadcast messages to all client applications, leaving each individual client application to decide for itself whether or not to process a particular message. This will not work for our application since there are a large number of market data messages being sent to each client application. If we broadcast market data updates to uninterested trader, we will be unnecessarily wasting client processor cycles deciding whether or not to process a market data update.
Point-to-Point Channels initially sound like a good choice since the clients are sending messages to unique servers and visa versa. But it was a business requirement that traders may be logged in to multiple machines at the same time. If we have a trader logged in at two workstations simultaneously and a point-to-point price update is sent, only one of the two client applications will get the message. This is because only one consumer on a Point-to-Point Channel can receive a particular message. Notice that only the first of each group of a trader's client applications receives the message.
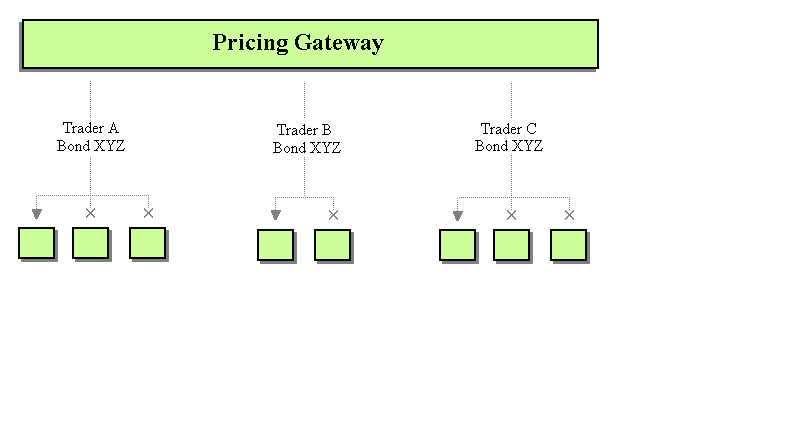
Point-to-Point Messaging for Price Updates
We could solve this using the Recipient List pattern, which publishes messages to a list of intended recipients, guaranteeing that only clients in the recipient list will receive messages. Using this pattern, the system could create recipient lists with all client application instances related to each trader. Sending a message related to a particular trader would in turn send the message to each application in the recipient list. This guarantees all client application instances related to a particular trader would receive the message. The downside of this approach is that it requires quite a bit of implementation logic to manage the recipients and dispatch messages.
Recipient List for Price Updates
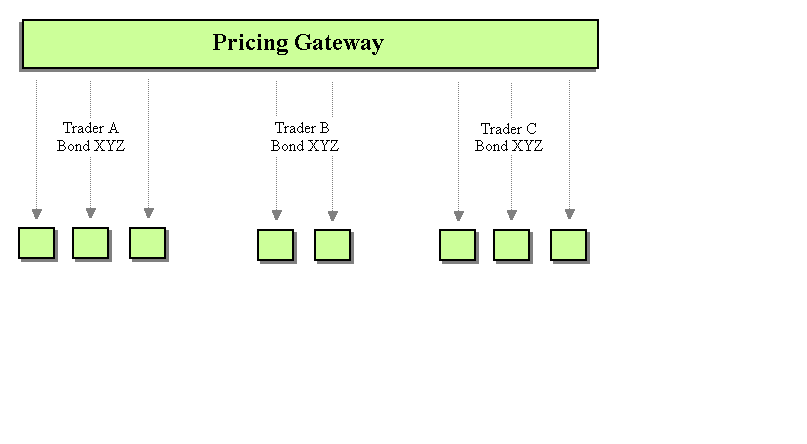
Even though point-to-point could be made to work, let’s see if there is a better way. Using Publish-Subscribe Channels, the system could broadcast messages on trader specific channels rather than client application specific channels. This way, all client applications processing messages for a single trader would receive and process the message.
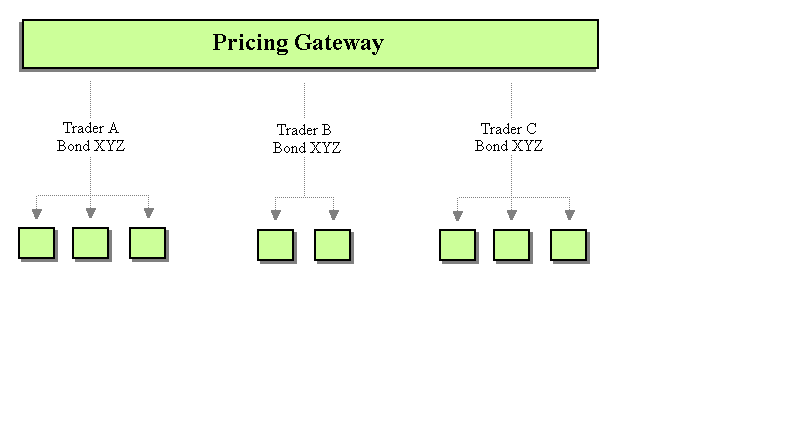
Publish-Subscribe Messaging for Price Updates
The downside of using Publish-Subscribe Channels is that unique message processing is not guaranteed with the server components. It would be possible for multiple instances of a server component to be instantiated and each instance process the same message, possibly sending out invalid prices.
Recalling the system message flow, only a single communication direction is satisfactory with each Message Channel. Server-to-client communication with publish-subscribe is satisfactory while client-to-server communication is not and client-server communication with point-to-point is satisfactory while server-client is not. Since there is no need to use the same Message Channel in both directions, we can use each Message Channel only one direction. Client-to-server communication will be implemented with point-to-point while server-to-client communication will be implemented with publish-subscribe. Using this combination of Message Channels, the system benefits from direct communication with the server components using point-to-point messaging and the multicast nature of publish-subscribe without either of the drawbacks.

Message flow with Channel Types
Problem Solving With Patterns
Patterns are tools and collections of patterns are toolboxes. They help solve problems. Some think that patterns are only useful during design. Following the toolbox analogy, this is like saying that tools are only useful when you build a house, not when you fix it. The fact is that patterns are a useful tool throughout a project when applied well. In the following sections we will use the same pattern exploration process we used in the previous section to solve problems in our now working system.
Flashing Market Data Updates
Traders want table cells to flash when new market data is received for a bond, clearly indicating changes. The Java client receives messages with new data which triggers a client data cache update and eventually flashing in the table. The problem is that updates come quite frequently. The GUI thread stack is becoming overloaded and eventually freezing the client since it can’t respond to user interaction. We will assume that the flashing is optimized and concentrate on the data flow of messages through the updating process. An examination of performance data shows the client application is receiving several updates a second; some updates occurred less than a millisecond apart. Two patterns that seem like they could help slow down the message flow are Aggregator and Message Filter.
A first thought is to implement a Message Filter to control the speed of the message flow by throwing out updates received a small amount of time after the reference message. As an example, lets say that we are going to ignore messages within 5 milliseconds of each other. The Message Filter could cache the time of the last acceptable message and throw out anything received within the next 5 milliseconds. While other applications may not be able to withstand data loss to such an extent, this is perfectly acceptable in our system due to the frequency of price updates.

Time based Message Filter
The problem with this approach is that not all data fields are updated at the same time. Each bond has approximately 50 data fields displayed to the user including price. We realize that not every field is updated in every message. If the system ignores consecutive messages, it may very well be throwing out important data.
The other pattern of interest is the Aggregator. The Aggregator is used to manage the reconciliation of multiple, related messages into a single message, potentially reducing the message flow. The Aggregator could keep a copy of the bond data from the first aggregated message, then update only new or changed fields successive messages. Eventually the aggregated bond data will be passed in a message to the client. For now, lets assume that the Aggregator will send a message every 5 milliseconds like the Message Filter. Later, we'll explore another alternative.
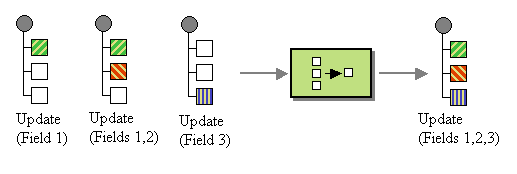
Aggregator with partial successive updates
The Aggregator, like any other pattern, is not a silver bullet; it has its pluses and minuses that need to be explored. One potential minus is that implementing an Aggregator would reduce the message traffic by a great amount in our case only if many messages are coming in within a relatively short time regarding the same bond. On the other hand, we would accomplish nothing if the Java client only receives updates for one field across all of the traders bonds. For example, if we receive 1000 messages in a specified timeframe with 4 bonds of interest, we would reduce the message flow from 1000 to 4 messages over that timeframe. Alternatively, if we receive 1000 messages in the same timeframe with 750 bonds of interest, we will have reduced the message flow from 1000 to 750 messages; relatively little gain for the amount of effort. A quick analysis of the message updates proves that the Java client receives many messages updating fields of the same bond, and therefore related messages. So, Aggregator is in fact a good decision.
What's left is to determine how the Aggregator will know when to send a message it has been aggregating. The pattern describes a few algorithms for the Aggregator to know when to send the message. These include algorithms to cause the aggregator to send out its contents after a certain amount of time has elapsed, after all required fields in a data set have been completed, and others. The problem with all of these approaches is that the aggregator is controlling the message flow, not the client. And the client is the major bottleneck in this case, not the message flow.
This is because the Aggregator is assuming the consumers of its purged messages (the client application in this case) are Event-Driven Consumers, or consumers that rely on events from an external source. We need to turn the client into a Polling Consumer, or a consumer that continuously checks for messages, so the client application can control the message flow. We can do this by creating a background thread that continuously cycles through the set of bonds and updates and flashes any changes that have occurred since the last iteration. This way, the client controls when messages are received and as a result, guarantees that it will never become overloaded with messages during high update periods. We can easily implement this by sending a Command Message to the Aggregator initiating an update. The Aggregator will respond with a Document Message containing the set of updated fields that the client will process.
The choice of Aggregator over Message Filter is clearly a decision based solely on the business requirements of our system. Each could help us solve our performance problems, but using the Message Filter would solve the problem at cost of the system data integrity.
Major Production Crash
With the performance of the flashing fixed, we are now in production. One day the entire system goes down. MQSeries crashes, bringing several components down with it. We struggle with the problem for a while and finally trace it back to the MQSeries dead letter queue (an implementation of the Dead Letter Channel). The queue grows so large that it brings down the entire server. After exploring the messages in the dead letter queue we find they are all expired market data messages. This is caused by “slow consumers,” or consumers that do not process messages fast enough. While messages are waiting to be processed, they time out (see the Message Expiration pattern) and are sent to the Dead Letter Channel. The excessive number of expired market data messages in the dead letter queue is a clear indication that the message flow is too great – messages expire before the target application can consume them. We need to fix the message flow and we turn to patterns for help slowing down the message flow.
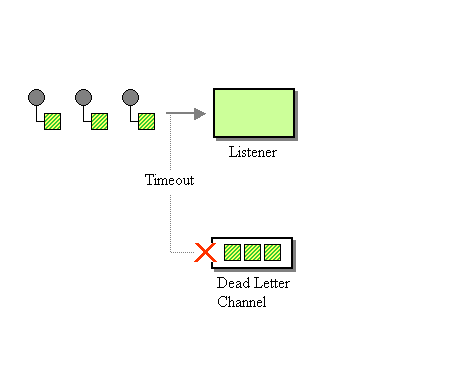
The bottleneck
A reasonable first step is to explore solving this problem with the Aggregator as we recently used this pattern to solve the similar flashing market data control rate problem. The system design relies on the client application to immediately forward market data update messages to the trading venues. This means the system cannot wait to collect messages and aggregate them. So the Aggregator must be abandoned.
There are two other patterns that deal with the problem of consuming messages concurrently: Competing Consumers and Message Dispatcher. Starting with Competing Consumers, the benefit of this pattern is the parallel processing of incoming messages. This is accomplished using several consumers on the same channel. Only one consumer processes each incoming message leaving the others to process successive messages. Competing Consumers, however, will not work for us since we are using Publish-Subscribe Channels in server-to-client communication. Competing Consumers on a Publish-Subscribe Channel channel means that all consumers process the same incoming message. This results in more work without any gain and completely misses the goal of the pattern. This approach also has to be abandoned.
On the other hand, the Message Dispatcher describes an approach whereby you add several consumers to a ‘pool’. Each consumer can run its own execution thread. One main Message Consumer listens to the Channel and delegates the message on to an unoccupied Message Consumer in the pool and immediately returns to listening on the Message Channel. This achieves the parallel processing benefit of Competing Consumers, but works on Publish-Subscribe Channels.
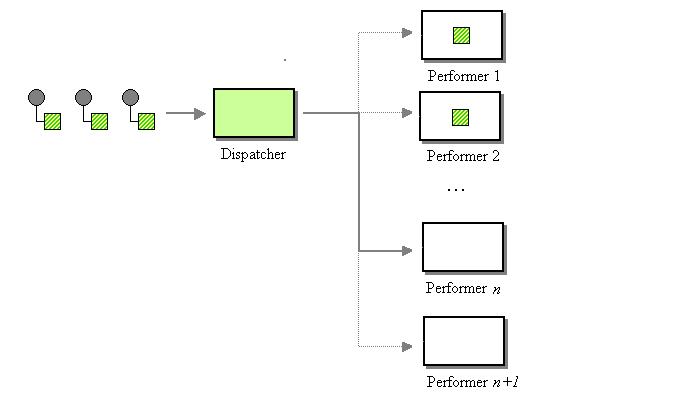
The Message Dispatcher in context
Implementing this in our system is simple. We create a single JMSListener called the Dispatcher, which contains a collection of other JMSListeners called Performers. When the onMessage method of the Dispatcher is called, it in turn picks a Performer out of the collection to actually process the message. The result of which is a Message Listener (the Dispatcher) that always returns immediately. This guarantees a steady flow of message processing regardless of the message flow rate. Additionally, this works equally well on a Publish-Subscribe Channels as it does on a Point-to-Point Channels. With this infrastructure, messages can be received by the client application at almost any rate. If the client application is still slow to process the message after receiving them, the client application can deal with the delayed processing and potentially outdated market data rather than the messages expiring in the JMS Message Channel.
The crash discussed in this section and the fix using the Message Dispatcher is an excellent example of the limits of applying patterns. We encountered a performance problem based on a design flaw not allowing the client to process messages in parallel. This greatly improved the problem, but did not completely fix it. This is because the real problem was the client becoming a bottleneck. This couldn’t be fixed with a thousand patterns. We later addressed this problem by refactoring the message flow architecture to route messages directly from the Pricing Gateway to the Contribution Gateway. So patterns can help design and maintain a system, but don’t necessarily make up for poor upfront design.
Summary
Throughout this chapter, we have applied patterns to several different aspects of a bond trading system including solving initial upfront design problems and fixing a nearly job threatening production crash with patterns. We also saw these patterns as they already exist in third party product, legacy components, and our JMS and TIBCO messaging systems. Most importantly, these are real problems with the same types of architectural, technical and business problems we experience as we design and maintain our own systems. Hopefully reading about applying patterns to this system helps give you a better understanding of the patterns as well as how to apply them to your own systems.
Integration Pattern Language