
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Find my posts on IT strategy, enterprise architecture, and digital transformation at ArchitectElevator.com.
While implementing the EIP Loan Broker Example on AWS, we realized that integration patterns are a useful design tool for serverless applications and can help us find meaningful abstractions for automation code. One argument that is routinely held against building serverless solutions, which I consider the canonical way of building cloud-native applications, is that they lock you into one vendor, meaning it's difficult to move them from one cloud platform to the next. Architects shun slogans and prefer to dig deeper, so let's do that by taking a well-designed serverless application and porting it to another cloud platform.
Interchangeability has long been a critical consideration of good software design: we choose abstractions so we can replace the implementations without the changes trickling through the rest of our system. So it'd seem natural to also want to maintain this ability when we aren't speaking of individual components but about a platform that we operate on. The counterpoint to this argument is that portability is a future concern whereas building a successful product is an immediate concern—without the latter you won't need the former.
As architects we look for balance in our designs, and we learned that the extrema of a spectrum are rarely the optima. That's why I warned a while ago to not get locked up into avoiding lock-in and to develop a holistic view on switching costs. And although I am a big fan of modern cloud architectures, I am critical of attempts to redefine "cloud native" to mean avoiding native cloud platform features. It's also outright silly naming as it contradicts what we mean when we have been saying "native app" for decades (see TechTarget ):
A native application is a software program that is developed for use on a particular platform or device.
Architects improve their decisions with models, but also regularly dive into the engine room to validate their assumptions. So, when debating the immediate merits of serverless architectures against a potential increase in future switching cost, it behooves us to inject some real-life data points into the discussion. The AWS serverless Loan Broker, which was built as a prototypical serverless application and has sufficient run-time complexity, makes a great data point. Let's port it to GCP!
Just like the prior posts, my write-up will be part experience journal, part architectural pondering. As an architect, it's less about the code I write but more about what insights I bring back with me from the engine room:
My goal isn't to develop a hardened production application but rather to reflect on the product architecture, available services, and design trade-offs.
I consider myself a good test subject because I have a clear idea of what I want to build, understand the technical domain (asynchronous, distributed apps) very well, but have near-zero expertise in the specifics of the platform, aside from having toyed with PubSub and Cloud Functions five years ago:
I understand the technical domain very well but am likely to make the same silly mistakes as other folks who are new to the platform.
As before, i will try to avoid installing any software locally by working in Cloud Shell and the console as much as possible. I am sure, it'll be possible to build the Loan Broker on GCP, so this isn't a test of the platform's capabilities as much as the platforms approachability:
My metric for the perceived cognitive load is the number of browser tabs that I need to open to accomplish a specific task.
As before all source code is available in the EIP GitHub repo. Keep in mind that this code is for educational purposed only and is not intended for production use.
Let's recap our starting point: a serverless cloud application that maximizes the use of managed services and follows serverless best practices of loosely coupled components, externalized state, and event-flow. Portability was a secondary concern when this app was built.
The Loan Broker implementation consists of the following key components, following a fine-grained, asynchronous design philosophy:
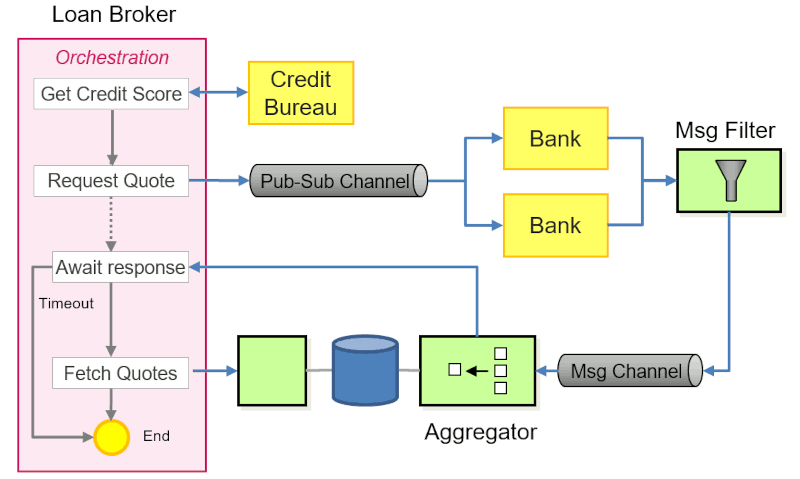
Let's quickly recap several key design decisions:
Armed with the source code of the AWS implementation, it shouldn't be too difficult to deploy the Lambda functions, which are now called Cloud Functions. A major overhaul of Google Cloud Functions is underway, which builds on top of Cloud Run. However those capabilities are still in preview and not available in Southeast Asia regions, close to where I am writing this. For our Loan Broker, 1st gen Cloud Functions should therefore easily suffice.
We can make relatively minor adjustments to the Credit Bureau source in the excellent GCP Cloud Shell editor:
const functions = require('@google-cloud/functions-framework');
function getRandomInt(min, max) {
return min + Math.floor(Math.random() * (max-min));
}
// Expects a SSN to return a random credit score. Passes back RequestId.
functions.http('CreditBureau', (req, res) => {
const min_score = 300
const max_score = 900
var ssn_regex = new RegExp("^\\d{3}-\\d{2}-\\d{4}$");
if (ssn_regex.test(req.query.SSN)) {
res.status(200).send(JSON.stringify(
{
request_id: req.query.RequestId,
body: {
SSN: req.query.SSN,
score: getRandomInt(min_score, max_score),
history: getRandomInt(1,30)
}
}
));
} else {
res.status(400).send(JSON.stringify(
{
request_id: req.query.RequestId,
body: {
SSN: req.query.SSN
}
}
));
}
};
Our Credit Bureau works synchronously, which in GCP parlance translates into an HTTP
function. That's why the function code accesses the incoming data via HTTP req and res parameters. This change caused the majority of code changes.
Starting out with basic automation (there's no CDK equivalent for GCP to my knowledge—most folks I know use Terraform), we deploy the Loan Broker function from the Cloud Shell Command Line (CLI):
$ gcloud functions deploy CreditBureau --region=asia-southeast1 \
--source=CreditBureau --runtime=nodejs14 --entry-point=creditBureau \
--trigger-http --allow-unauthenticated
Although the parameters appear intuitive enough, my initial attempt is punished with an elaborate but not very insightful error message:
ERROR: (gcloud.functions.deploy) OperationError: code=3, message=Function failed on loading user code. This is likely due to a bug in the user code. Error message: Error: please examine your function logs to see the error cause: https://cloud.google.com/functions/docs/monitoring/logging#viewing_logs. Additional troubleshooting documentation can be found at https://cloud.google.com/functions/docs/troubleshooting#logging. Please visit https://cloud.google.com/functions/docs/troubleshooting for in-depth troubleshooting documentation.
That makes for two additional tabs open and public embarrassment for omitting the
package.json file to declare the dependency on google-cloud/functions-framework. Correcting that mistake is rewarded with a deployed credit bureau (shortened for
readability):
$ gcloud functions describe CreditBureau --region=asia-southeast1 availableMemoryMb: 256 entryPoint: creditBureau httpsTrigger: securityLevel: SECURE_OPTIONAL url: https://asia-southeast1-eaipubsub.cloudfunctions.net/CreditBureau name: projects/eaipubsub/locations/asia-southeast1/functions/CreditBureau runtime: nodejs14 status: ACTIVE timeout: 60s versionId: '3'
Invoking the credit bureau is equally easy from Cloud Shell via curl (don't forget the double quotes as your shell won't like the ampersand in the query
string otherwise):
$ curl "https://asia-southeast1-eaipubsub.cloudfunctions.net/CreditBureau?RequestId=ABCDEFG&SSN=123-45-6789"
{"request_id":"ABCDEFG","body":{"SSN":"123-45-6789","score":470,"history":4}}
We note that in GCP, the application trigger is set right on deployment. That's convenient, but it also propagates code changes into the function should you decide to change the trigger. We learn that:
Separating function invocation and data passing logic, such as request data parsing, return codes, etc., from application logics is good practice because it simplifies both changing triggers and porting functions to another platform.
Unlike the Credit Bureau, our Banks will receive requests for mortgage quotes via GCP Pub/Sub, which conveniently supports both Point-to-Point channels and Publish-Subscribe Channels. Interestingly, there's no "integration" service category for GCP, so we find Pub/Sub under "Data Analytics":

Besides small differences in the way data is based (a base64-encoded string), the
code can remain largely unchanged. GCP Cloud Functions do not have destinations, so
the function has to send the response message explicitly. We therefore need to pass
the topic name as an environment variable. Also, the message accepts a Buffer as opposed to a regular string, so don't forget that conversion. To keep our function
code clean, we extract that logic into a wrapper method. A base class might be an
even more elegant solution.
const {PubSub} = require('@google-cloud/pubsub');
const pubSub = new PubSub();
function calcRate(amount, term, score, history) {
if (amount <= process.env.MAX_LOAN_AMOUNT && score >= process.env.MIN_CREDIT_SCORE) {
return parseFloat(process.env.BASE_RATE) + Math.random() * ((1000 - score) / 100.0);
}
}
exports.bank = async (message, context) => {
const request = message.data ? Buffer.from(message.data, 'base64').toString() : '{}';
const quoteRequest = JSON.parse(request);
const requestId = message.attributes["RequestId"];
const bankId = process.env.BANK_ID;
const responseTopic = process.env.QUOTE_RESP_TOPIC;
response = bankQuote(quoteRequest, bankId);
const dataBuffer = Buffer.from(JSON.stringify(response));
const customAttributes = { id: requestId };
const messageId = await pubSub.topic(responseTopic).publish(dataBuffer, customAttributes);
}
bankQuote = (quoteRequest, bankId) => {
const rate = calcRate(quoteRequest.Amount, quoteRequest.Term, quoteRequest.Credit.Score, quoteRequest.Credit.History);
if (rate) {
console.log('%s offering Loan at %f', bankId, rate);
return { "rate": rate, "bankId": bankId };
} else {
console.log('%s rejecting Loan', bankId);
return {};
}
}
Subscribing a Cloud Function to a PubSub topic is surprisingly easy and can be done
straight from the deployment command. Under the covers, it creates a subscription, a key construct of PubSub that determines whether you're running in Publish-Subscribe or Point-to-Point mode with Competing Consumers. See my post on Google Cloud Pub/Sub from 2015 for more details.
$ gcloud pubsub topics create QuoteRequest
$ gcloud pubsub topics create QuoteResponse
$ gcloud functions deploy BankPawnShop --entry-point=bank --region=asia-southeast1 \
--source=Bank --runtime=nodejs14 --trigger-topic QuoteRequest \
--set-env-vars MAX_LOAN_AMOUNT=500000,MIN_CREDIT_SCORE=300,BASE_RATE=3,BANK_ID=PawnShop,QUOTE_RESP_TOPIC=QuoteResponse
It's time for a simple test (after we deploy two more banks). We monitor the responses
on the QuoteResponse topic via an additional subscription, which is side-effect free in the Publish-Subscribe
model. To test, we send a message to the QuoteRequest channel and observe the bank's response on the QuoteResponse topic:
$ gcloud pubsub subscriptions create responses --topic=QuoteResponse
$ gcloud pubsub topics publish QuoteRequest \
--message='{ "Amount": 300000, "Term": 30, "Credit": { "Score":700, "History": 15 } }' \
--attribute=RequestId=ABCDEFG
$ gcloud pubsub subscriptions pull responses --auto-ack --limit=5
DATA: {"rate":4.655600086643112,"bankId":"BankPremium"}
MESSAGE_ID: 4856059258002262
ATTRIBUTES: id=ABCDEFG
DATA: {"rate":5.8170958335644,"bankId":"BankUniversal"}
MESSAGE_ID: 4856047506661721
ATTRIBUTES: id=ABCDEFG
DATA: {"rate":7.206690977561289,"bankId":"BankPawnshop"}
MESSAGE_ID: 4856047534743250
ATTRIBUTES: id=ABCDEFG
Yup, this works. Time for a quick pause and some initial observations.
Overall, re-implementing the serverless functions on GCP is relatively pain-free. Most of the design constructs translate 1:1 into the new platform. Of course, there are also some surprises - positive and negative, which may partly be due to my unfamiliarity with the new platform. Again, I consider that a plus because when I stumble, it's likely because something in the platform isn't as intuitive as it could be.
EventSourceMapping etc. Also, a single service implements both Publish-Subscribe and Point-to-Point semantics.
In summary, I am inclined to claim:
A clean and evocative design that highlights design decision makes migrating a serverless application to a new platform significantly easier.
Let's try to back this up as we proceed to implement the orchestration and the Aggregator.
Orchestrations are implemented using GCP's Workflows. Just like AWS Step Functions, GCP Workflows follow a state machine model that allows for sequences, loops, branching, and error states. GCP Workflows are also coded in a custom language that uses YAML or JSON syntax - pick your poison. I wasn't able to find a formal language specification analog to the Amazon States Language, but there's a useful Syntax Overview.
I couldn't help but detect some irony in the fact that AWS Step Functions calls its elements States whereas Google Workflows calls them Steps.
GCP Workflows don't have a visual editor, so we're finding ourselves counting indents to get our YAML file to parse. Syntax checking in the console editor and a quasi-real time (read only) visualization provide some support as we type along.
The first step in our workflow Enriches the incoming request with the requestor's credit worthiness. Most interactions between
the workflow and the outside world are handled via a Call step, which can utilize a variety of Connectors.
Just as with Step Functions, we can pass arguments into the workflow and prepare the request data format. We then invoke the Credit Bureau with a synchronous HTTP call. In GCP Workflows YAML, this looks as follows (as always, the source code is available in the public EIP repo):
main:
params: [input]
steps:
- init:
assign:
- project: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- location: "asia-southeast1"
- topic: "QuoteRequest"
- get_function:
call: googleapis.cloudfunctions.v1.projects.locations.functions.get
args:
name: ${"projects/" + project + "/locations/" + location + "/functions/CreditBureau"}
result: creditBureau
- getCreditScore:
call: http.get
args:
url: ${creditBureau.httpsTrigger.url}
query:
RequestId: ${sys.get_env("GOOGLE_CLOUD_WORKFLOW_EXECUTION_ID")}
SSN: ${input.SSN}
result: creditBureauResponse
Unlike Step Functions, Workflows assumes an implicit sequence of the steps, so that
a next element isn't required for simple sequential workflows. Just as before, we can access
a select set of predefined variables, including project names and workflow execution ID, with the latter being a convenient
source for a unique Correlation Identifier. Custom arguments can be passed in from the command line or the workflow trigger
and accessed via the variable specified as params. All this feels quite intuitive.
Invoking a cloud function via HTTP requires the function URL. Following one of the
examples, the flow fetches the URL via an API call. You could also retrieve it from
the command line via functions describe and pass it as a parameter to the workflow. If specifying the function name in the
workflow smells like tight coupling, I'd agree with you. We would want to separate
composition from logic.
Armed with a richer data set, our workflow is ready to send a request for quote to any participating banks via a PubSub topic:
- setQuoteRequest:
assign:
- creditScore:
${json.decode(creditBureauResponse.body).body}
- quoteRequest:
SSN: ${input.SSN}
Amount: ${input.Amount}
Term: ${input.Term}
Credit:
Score: ${creditScore.score}
History: ${creditScore.history}
- base64Msg: ${base64.encode(json.encode(quoteRequest))}
- sendQuoteRequest:
call: googleapis.pubsub.v1.projects.topics.publish
args:
topic: ${"projects/" + project + "/topics/" + topic}
body:
messages:
- data: ${base64Msg}
attributes:
RequestId: ${sys.get_env("GOOGLE_CLOUD_WORKFLOW_EXECUTION_ID")}
As we experienced before, some of the lines implied more hurdles than one might guess from the result. For
example, understanding what data is passed as a string vs. JSON vs. stringified JSON
vs. a base64-encoded string took a good bit of finessing. Likewise, expressions like
${json.decode(creditBureauResponse.body).body} didn't come easily (at least to me), as the first body derives from the http.get return format and contains a stringified JSON. The second body is the field name chosen by our Credit Bureau implementation, which is contained
in the JSON, which is stringified in the first body. Of course, in hindsight that all seems obvious, but without types nor auto-complete,
and somewhat tedious logging, it took longer to get working than I'd like to admit.
To make things ever more fun, PubSub messages ought to be base64 encoded, unlike the
attributes, which, however, have to be in form of a map, not a list. Misplacing the - cost me nerves and the better part of one hour.
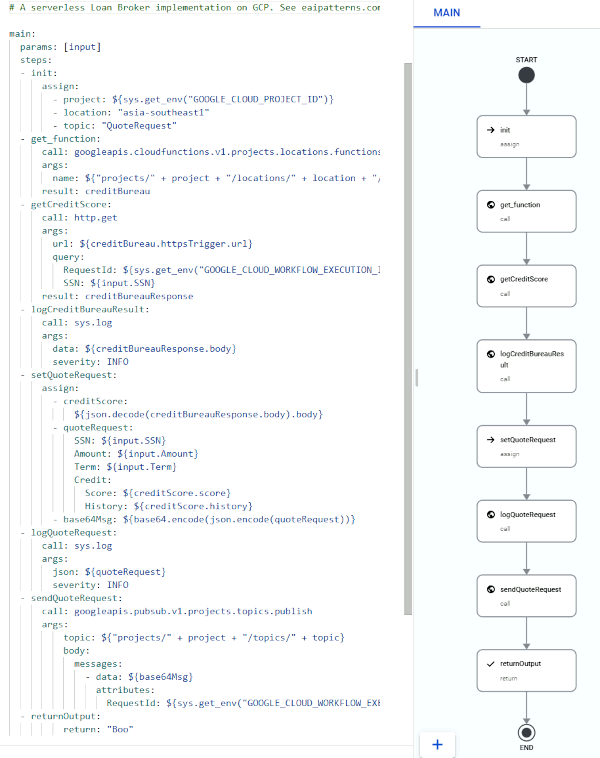
I could not have managed to get this to work without inserting additional logging steps into the workflow. It appears that cloud workflow tools tend to focus on the control flow over data handling, even though the latter is at least as important. The basic flow so far already looks a bit longer than intended, as shown on the right.
Let's take a pause for a quick recap and first impressions.
call steps do not include result data transformations as they do in Step Functions, leading
to the addition of two assign steps. It might be possible to squeeze the creation of the quoteRequest message into the call step, but I am quite happy to have separated creation of the JSON structure, stringification,
and base64 encoding. Two additional steps are init and return, which currently don't do much, but that's how we got from two essential states to
eight in total.
step elements in the YAML document is handy. Step Functions wants you to provide an explicit
next element with each step (task), which makes inserting logging or assignment steps
slightly more tedious (although the Workflow Studio takes care of that mostly).
attributes field takes a map of values. Translating that into the Workflows YAML took a fair
bit of creativity and guesswork (my deliberate lack of YAML experience might have
exacerbated the situation).
Overall, you can tell that this service hasn't had as much time to mature the developer
experience as its AWS counterpart (Dec 2016 vs. Jan 2021). At the same time, the concepts
feel quite familiar to someone coming from AWS and it's likely that most orchestrations
port over fairly well, although you'd have to recode it in the new syntax. The absence
of a map construct might be the only major hurdle.
Sending quote requests is fine, but aggregating quote responses from an unknown number of banks is where the messaging rubber meets the cloud platform road. The AWS implementation used a lambda function written in Python with DynamoDB as the backing data store. In GCP land, that'll translate into Cloud Functions with Datastore, or rather Firestore in Datastore mode. When it comes to naming, all cloud providers apparently have their weak spots.
First, we'll need to create a data store. That should be easy enough, but for some
reason, Firestore data stores are tied to App Engine, which is tied to a region, which
you can't change. Off we go, create a new project, a new app (which we don't actually
need) and a new datastore (someone grant me the serenity …):
$ gcloud app create --region=asia-southeast1 $ gcloud datastore databases create --region=asia-southeast1 Success! Confirmed selection of a Google Cloud Firestore in Datastore Mode database for eiploanbroker
GCP Datastore stores Entities, which equate to rows in a relational database. You can fetch them with a key and add new ones by instantiating one with a key and puting it into the data store. As Datastore appears to lack an append operation, we must wrap reading and writing into a transaction to avoid conflicting
operations and data loss. As before, just for fun, we write the Aggregator in Python (source code in EIP repo):
def store_quote(correlationId, quote):
key = db.key("MortgageQuotes", correlationId)
with db.transaction():
item = db.get(key)
if not item:
item = datastore.Entity(key)
item['Quotes'] = []
item['Quotes'].append({ 'bankId': quote['bankId'], 'rate': quote['rate'] })
db.put(item)
logging.info(item)
return item
Although method names change, the code remains quite similar to the AWS version. Again,
wrapping the logic in a helper method localizes such changes. We might even be able
to avoid the if statement by using get_multi, but I didn't want to push my luck.
Time to wire this together and give it a shot. We test by publishing messages to the
QuoteRequest topic directly, bypassing the workflow.
$ gcloud functions deploy Aggregator --source=Aggregator --entry-point=handle_quote \
--region=asia-southeast1 --runtime=python39 --trigger-topic=QuoteResponse
$ gcloud pubsub topics publish QuoteRequest \
--message='{ "Amount": 300000, "Term": 30, "Credit": { "Score":700, "History": 15 } }' \
--attribute=RequestId=ABDD
Off we go! Our Aggregator doesn't yet signal back to the workflow, so we check the results in the log:
google.api_core.exceptions.Aborted: 409 Aborted due to cross-transaction contention. This occurs when multiple transactions attempt to access the same data, requiring Firestore to abort at least one in order to enforce serializability.
Oops. That didn't work. So we took care to use transactions but Datastore doesn't seem to like conflicting transactions.
The docs didn't help me much, aside from proposing to reduce updates on individual documents
to one per second, which doesn't exactly sound like an infinitely scalable serverless
data store. My initial fix is to limit the Aggregator cloud function to a single instance by adding a --max-instances option:
$ gcloud functions deploy Aggregator --source=Aggregator --entry-point=handle_quote \
--region=asia-southeast1 --runtime=python39 --trigger-topic=QuoteResponse --max-instances 1
This solves the concurrency issue but appears overly restrictive as contention only
occurs for responses on one individual loan request to the Loan Broker. A quick scan
of the logs suggests execution times for the Aggregator function of about 140ms, which would process only 7 quotes per second if we limit
to a single instance:
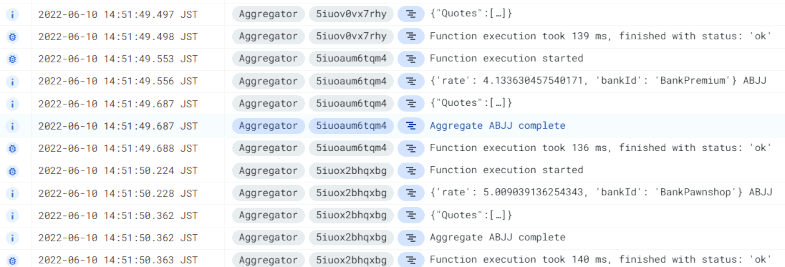
That isn't great and something we should fix. On the upside, we got exactly what we were looking for:
Despite its apparent simplicity, the EIP Loan Broker quickly reveals many nuances and challenges in asynchronous, distributed applications.
A better solution than throttling updates is to retry on failure. This will work well
because the transaction failures are transient, meaning they are likely to succeed
just a short time later. Luckily, GCP has a built-in option to retry message delivery
on error per the --retry command line option on function deployment.
$ gcloud functions deploy Aggregator --source=Aggregator --entry-point=handle_quote \
--region=asia-southeast1 --runtime=python39 --trigger-topic=QuoteResponse --retry
Any failures stemming from transaction contention now cause the message to be re-delivered
and the Aggregator function to be re-executed. This way we don't have to compromise the happy path to
accommodate a relatively rare error condition. The retry documentation advises to make retried functions idempotent. Strictly speaking, ours isn't as it'll append the same quote twice. However, if
the error resulted from a data store insert in the first place, that won't be a problem. We could relatively easily make the
function idempotent by replacing the Quotes list with a map indexed by BankId. The docs also warn of potentially infinite retries caused by application errors,
which I can confirm (deleting the topic seems to get you out of it at the price of
total data loss). You'd therefore want to catch any errors that shouldn't trigger
a retry, ignore old messages (essentially implementing your own TTL), and use the
--retry flag only after thorough testing.
Run-time considerations like contention, re-try logic, back pressure, infinite loops make up a large portion of designing and building distributed, asynchronous applications.
One part from the original design that we didn't yet implement is the Message Filter that eliminates empty responses from banks that aren't interested in the loan application. AWS handled this nicely with EventBridge rules. GCP EventArc might be a usable option, but I'll have to check into that later. For now, I add a simple condition into the aggregator code:
if not 'bankId' in quote:
logging.warning("incomplete quote received")
return 0
This of course works, but it blurs the role of the Aggregator with that of the Message Filter. It's up to you if you consider that acceptable. Another feature lacking from our implementation is purging of aggregate data from the database. Right now, our entities just keep accumulating, but for this simple experiment that's alright.
As a last step, the Aggregator needs to signal to the workflow that an aggregate is complete, meaning a sufficient number of quotes have been received. Workflows supports Callback endpoints, which is a perfect match for this use case. A special library call creates a unique callback URL, which you can pass to an external task. You can then pause the workflow until that URL is invoked or you reach a time-out. Similar to AWS Step Functions, GCP Workflows allow the caller to pass data back with the callback by performing a POST.
The easiest way to pass the callback URL to the Aggregator is via the id message attribute that's already in place and propagated by the banks. Because the
callback URL is unique to each workflow instance, this field can act both as a Correlation Identifier and as callback address.
We add the following steps to the workflow (see source):
- create_callback:
call: events.create_callback_endpoint
args:
http_callback_method: "POST"
result: callback_details
[send request message as before]
- await_callback:
try:
call: events.await_callback
args:
callback: ${callback_details}
timeout: 30.0
result: aggregate_quotes
except:
as: e
steps:
- log_error:
call: sys.log
args:
severity: "WARNING"
text: ${"Error " + e.message}
next: end
- print_callback_data:
call: sys.log
args:
severity: "INFO"
text: ${aggregate_quotes}
- returnOutput:
return: ${aggregate_quotes.http_request.body}
The callback result comes back as a JSON element embedded in the http_request.body of the request object (this might once again seem apparent after some mandatory logging
and debugging content types and encodings).
The following code in the Aggregator sends the required callback signal with attached aggregate data:
def completion_callback(correlationId, aggregate):
logging.info("Aggregate complete: %s", correlationId)
url = correlationId
auth_req = google.auth.transport.requests.Request()
creds.refresh(auth_req)
status = requests.post(url, json=aggregate, headers={"Authorization": f"Bearer {creds.token}"})
logging.info("Sent Callback: %i", status.status_code)
While I escaped IAM so far, these callbacks do require an authentication token. Luckily,
you can fetch one from google.auth.transport.requests as both the workflow and the function operate under the same service account. This
code once again looks simple but took a good amount of digging through the docs and Stack Overflow. The python requests library allows us to conveniently pass a JSON object back to the workflow. Overall,
the cognitive load of this async callback, measured in open browser tabs, was rather
high at about 8 tabs, more than the lines of code.
The number of open browser tabs to check documentation and examples exceeded the lines of code.
Architects should have a lot of appreciation for life in the engine room.
Let's give the whole setup a run-through:
QuoteRequest.
QuoteResponse if they are willing to service the loan. Otherwise, they send an empty message.
QuoteResponse and stores them into Firestore, indexed by the correlation identifier.
From the gcloud command line, this looks somewhat less exciting, but that's likely a good thing (minor formatting done by the operator):
$ gcloud workflows deploy LoanBrokerCallback --source=LoanBrokerFlowCallback.yml \
--location=asia-southeast1
$ gcloud workflows execute LoanBrokerCallback --location=asia-southeast1 \
--data='{ "Amount": 300000, "SSN": "123-45-1113", "Term": 10 }'
Created [284be31c-f5dd-4978-9538-123456789]
$ gcloud workflows executions describe 284be31c-f5dd-4978-9538-123456789 \
--workflow=LoanBrokerCallback --location=asia-southeast1
argument: '{"Amount":300000,"SSN":"123-45-2211","Term":10}'
endTime: '2022-06-12T11:38:00.248691113Z'
startTime: '2022-06-12T11:37:50.357602769Z'
state: SUCCEEDED
result: '{"Quotes":[
{"bankId":"BankPawnshop","rate":6.415049525230497},
{"bankId":"BankPremium","rate":4.537483020303889}
]}'
Due to our Aggregator's simplistic completion condition, the Aggregator function may invoke the workflow callback more than once, e.g. when all three banks respond with a quote. That actually works OK as the second invocation of the callback URL simply returns a 404 HTTP code - these URLs are for one-time use only. This also means that we should invoke the callback near the end of our function. Otherwise function errors occurring after the callback would trigger a message delivery retry, which would not be able to invoke the callback again.
This solution works, but it's by no means production ready. For example, the following aspects would still need to be addressed:
As our professor would say, we leave those enhancements as an exercise to the reader.
Despite leaving several "to do's", the EIP Loan Broker application mapped quite well onto GCP's serverless platform. It also revealed several important nuances for serverless application development:
Expressing our solution with the Integration Patterns vocabulary provided a significant
head start for the implementation because they highlight the solution structure and
critical design decisions in platform-independent terms. In each platform, those design
decisions map into different implementation details, sometimes spanning multiple services.
For example, on GCP the details of Datastore transactions for the Aggregator implementation
influence PubSub subscription settings (--retry). The design patterns pull these aspects together and allow us to build a correct
and reusable implementation.
Both platforms support the integration patterns well and the resulting solution architecture is comparable. However, I noticed significant differences in developer tooling. For example, although I occasionally deride Doodleware, AWS Workflow Studio is a godsend for designing an initial workflow structure. Also, data manipulation feels more like a first class concern on AWS Step Functions, although each workflow instance is limited to a single JSON document.
On the flip side, I really enjoyed the GCP Cloud Shell editor: you almost forget that you are working in a browser. Also, switching between editor and shell in a single tab feels natural. Git integration is trivial.
AWS clearly has had more time to mature the serverless ecosystem, not only with tooling, but also with concepts like Destinations, which nicely separate composition from application logic. Also, EventBridge is a very good match for Message Transformation and Message Routing patterns. GCP EventArc is still in preview, so we'll need to see how close it can come. For now it seems that its event filters are less expressive than EventBridge Rules. GCP Workflows are lacking parallel execution (an experimental option is available). And GCP lacks a built-in automation tool like CloudFormation or AWS CDK. None of these are show stoppers, but you don't want to end up playing Takeshi's Castle.
Both platforms have their quirks, things that appear obvious once you know them, but until then seem insurmountable. AWS IAM tends to nib you in the rear whenever it can and also has a curious structure of IAM roles and resource-based policies (as I said they make total sense once you get your head around it). GCP Datastore requiring you to setup an AppEngine project and being bound to that projects region seems equally arbitrary. The light at the end of the tunnel is that you're likely to face those learning cliffs only once.
Last, modern cloud platforms are vast and powerful, so finding all docs to be approachable, meaningful, precise, and easy to discover might be asking for a lot. Still, I found myself opening more tabs across product docs, tutorial, quick starts, and Stack Overflow for GCP than I had to for AWS (and my starting point was equally ignorant).
The old joke that you need at least 10 AWS services on to write "Hello World" basically held true during the initial Loan Broker implementation. Mathematically speaking, GCP used fewer services. However, aside from Pub/Sub being a single service whereas it's split into SQS and SNS on AWS, the difference is largely due to the absence of some services that we would have liked to use. Here is the current service mapping for our solution:
Function AWS GCP Comment -------- --- --- ------- Serverless Function Lambda Cloud Functions Orchestration Step Functions Workflows 1:many messaging SNS PubSub 1:1 messaging SQS PubSub Key Value Store DynamoDB Datastore Logging CloudWatch Logging Development Cloud Shell Cloud Shell Automation CloudFormation/CDK (none) 3rd party, often Terraform Event Router EventBridge (EventArc) In preview, fewer filter capabilities Access Management IAM (IAM) Didn't explicitly use, but should have
Once you factor in 3rd party services or services in preview, the number of services involved is comparable. Both platforms allowed me to fully build the Loan Broker without any local installation, which is impressive.
Our test did not address how the solution behaves under heavy load and error conditions. This is where scaling policies, quotas, message deliver guarantees, etc. will come into play.
The key question we posed at the beginning was related to "lock-in" or rather switching costs from one platform top another. A common argument building using serverless solutions, despite the apparent advantages, is the perceived difficulty of porting code from one platform to another if the need arises. I have already discussed the value and cost of options and the danger of forgoing today's feature delivery velocity for a reduction in tomorrow's potential switching cost. For serverless solutions the lost opportunity cost appears particularly high.
Building the Loan Broker on GCP wasn't a mechanical port. However, having expressed the solution in form of Integration Patterns gave me a significant head start because the key design decisions were expressed independent of the platform. If I had structured the original solution code with cleaner abstractions between pattern and platform, I likely would have been able to re-use most actual application logic without minimal changes. Based on the data point gathered from the Loan Broker, I venture to state:
A clean design based on integration patterns improves code structure such that moving the solution to a different platform is much simplified.
Pattern-based design therefore helps you build a better solution now, and also makes it easier to move it, if you should ever have the need. This insight is profound enough that it'll deserve its own post. Stay tuned.


 Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.
Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.