
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Find my posts on IT strategy, enterprise architecture, and digital transformation at ArchitectElevator.com.
My last rambling from, ahem, 2017 transported the integration patterns into the era of serverless compute. After implementing a Content-based Router as a Google Cloud Function, I want to be a bit more ambitious this time and implement the book's venerable Loan Broker Example using AWS Lambda and AWS Step Functions.
So, it's time for the hands-off architect(TM) to get the hands dirty! I expect it to be the first in a series where I share my first-time experience with popular tools. Having a lot of expertise in the technical domain but absolutely no clue about the product likely makes me a tough customer. So, be prepared for deep architecture insight coupled with UI hiccups and occasional ignorance.
I can't help but feel a sense of nostalgia while I am writing about AWS Step Functions
in an XML document (hello, <h2>, good bye, ##!) that's being rendered by an Ant script, which kicks off a chain of XSLT transformations. Ant 1.10.10 just having
been released a few months ago makes me feel like the setup isn't as retro as one
might think. For my part, I was happily surprised that the decade-old Ant script executes
flawlessly from my Windows GIT bash console. And nothing beats running ant clean to blow away all your output because you know you'll get a fresh build in just a
few seconds thanks to the lack of any external dependencies. It almost feels like
you're using GitHub pages :-) .
The use case I will implement is the original Loan Broker example from our book that served as the "Composed Messaging" example:
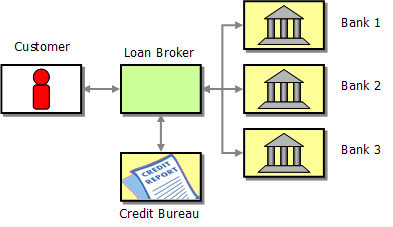
It's a relatively basic integration scenario that describes a simplified loan broker business:
Despite its simplicity, this scenario highlights many design options and trade-offs
involved in building asynchronous distributed solutions, including state management,
correlation, coupling, error handling, and many more. The book included implementations
with Web Services (a novelty at the time!), MSMQ (still going in Windows 10 - try More Windows features!), and TIBCO (the days of ActiveEnterprise are long gone but it's still one of the most robust
messaging systems). A little later we described a detailed implementation in BizTalk Server 2004. So, it's time for some cloud and serverless action!
When architects look at integration products like AWS Step Functions they don't just walk through the tutorials and "Get Started" instructions. Rather, they are interested in the product team's critical decisions and associated trade-offs. This makes us quite demanding customers in a way but perhaps also more interesting ones.
AWS Step Functions describes itself as "a low-code visual workflow service used to orchestrate AWS services, automate business processes, and build serverless applications". In plain English that means it's a Process Manager with the recent and welcome addition of a visual Doodleware editor. "Low-code" means that any logic that can't be represented visually will be painstakingly typed (or more likely pasted) in as JSON fragment, a JsonPath expression, or a JMESPath query.
The AWS console page details AWS Step Functions as "a serverless function orchestrator that makes it easy to sequence AWS Lambda functions and multiple AWS services into business-critical applications". That's a bit more concrete. I hope it'll forgive me for not building anything business critical this time around.
Behind the buzzword soup lies a lightweight orchestrator that executes state machine definitions as long as they don't contain complex loops and/or logic. Its main strength lies in the seamless integration with many AWS services, making it simple to invoke orchestrations via a call to the API Gateway, then storing or fetching data from a database, calling a Lambda function, and sending messages to SNS or SQS. The visual editor makes building such service orchestrations relatively straightforward.
So, what design decisions and trade-offs does Step Functions include? Let's start simple, acknowledging that we are working with a state machine, not a full-blown workflow / business process engine:
Workflow tools either model states (which makes it easy to track the current state) or activities (often more natural as the purpose of these flows is to coordinate activities). As the name "state machine" would suggest, Step Functions models states using the Amazon States Language. That's different from BPMN, which is based on activities. Interestingly, Step Functions includes "Task" states, which are called "Actions" in the GUI, and also "Activities". So, there appears to be a notion of orchestrating activities of sorts. We'll see how this plays out later on.
 In addition to the current execution state, most workflow engines manage a current
data set (document likely isn't the greatest name for it but it avoids confusion with
the state of execution). They accumulate data into that document / data set and transport
across the individual steps.
In addition to the current execution state, most workflow engines manage a current
data set (document likely isn't the greatest name for it but it avoids confusion with
the state of execution). They accumulate data into that document / data set and transport
across the individual steps.
Step Functions does this by keeping an active JSON document, which is manipulated
by task executions. Oddly, it doesn't seem to have a name but rather it shows up via
the Input settings for a task. In addition to filtering and transforming, you can also merge the task output with the input, effectively accumulating state. I wish this data management aspect was a bit more
visible in the Workflow Studio.
Powerful workflow engines allow an instance to be triggered by different incoming events and can correlate events to existing workflow instances to enable flows like the discriminator pattern.
Step Functions takes it a bit simpler with a single starting point, triggered for example via a call to an API Gateway. That's totally fine for an orchestrator - we aren't looking to build a business process modeling tool. Step Functions does have a callback mechanism, meaning asynchronous operations can call back into a running process via API by providing the correct Correlation Identifier that's derived from the task ID.
 Long-running processes need to deal with local error conditions like time-outs as
well as achieving some sort of consistency across long-running processes, e.g. through
compensating transactions in a Saga pattern.
Long-running processes need to deal with local error conditions like time-outs as
well as achieving some sort of consistency across long-running processes, e.g. through
compensating transactions in a Saga pattern.
Step Functions handles local errors via time-outs and retries with exponential back-off. Per the (marketing) home page it supports Sagas but it doesn't appear to be a built-in feature (an older blog post shows one implementation). Because you can define error states and route to them if a state encounters a specified error class you can likely implement common error handling mechanisms but it might make the resulting flows more complex.
 Workflow engines never live in isolation but coordinate activities across other systems
or functions. This is where Step Functions shines: you have anything from a Lambda
function invocation to a SNS notification or a DynamoDB update at your fingertips.
On top of that you can create EKS clusters. EMR (MapReduce) clusters and Sagemaker
models. The long list of AWS services highlights Step Functions' role as an automation
hub for AWS services.
Workflow engines never live in isolation but coordinate activities across other systems
or functions. This is where Step Functions shines: you have anything from a Lambda
function invocation to a SNS notification or a DynamoDB update at your fingertips.
On top of that you can create EKS clusters. EMR (MapReduce) clusters and Sagemaker
models. The long list of AWS services highlights Step Functions' role as an automation
hub for AWS services.
Iterative development and debugging is the Achilles heel of many integration and workflow tools. They assume that you know everything upfront, enter it once and 100% correct into the tool, and live happily ever after while promotions and pay raises keep rolling in. If you know any developer who works like that, please send them my way.
Step Functions doesn't seem to have the ability to pause or restart a partially executed
flow for inspection. But it does have a nifty event history that allows you to dig
into what went wrong. I used it mostly to see what the current document set looks
like and this would have liked to be able to stored intermediate data so I can test
a subsequent state I am working on. It'd be similar to saved data sets for Lambda
functions. Running state machines from the command line (CLI) or inserting a Pass state with hard-coded data is a reasonable work-around for simple cases. Still, I
spent 90% of my development time switching between an execution log, a JSONPath evaluator, and a task definition.
Overall, Step Functions looks well-rounded as a state engine for service and function orchestration with many built-in integrations. Also, it can't be mistaken for a full-blown process management tool like Camunda and friends.
Now it's time to bring those concepts into action by building out the Loan Broker example. As I am all fired up to enter the world of serverless orchestration, I'll start by building a Step Functions state machine for the Loan Broker.
Alas... embarrassingly I can't quite figure out how to create a process definition:
"Get Started" wants to create a pre-made sample, which while surely well-intended, makes me wonder
if we hadn't relegated copy-paste programming to Stack Overflow instead of baking
it right into the tool. The rest of the screen seems to have been leased to the marketing
department--a bit late for someone who already opened the console and is looking for
the Create button?
Getting ready to revert back to the command line, the low-code label encourages me to give it an extra round of mouse hunting, and voilà, the Hamburger menu on the left includes a "State machines" entry, which I assume is local lingo for a process template. Sure enough, clicking on it yields a big orange button to create a new one, pushing back the time to visit Stack Overflow by a good bit.
Step Functions must know that I am an architect: it's asking me to make the big decisions that are difficult to change later (TM):
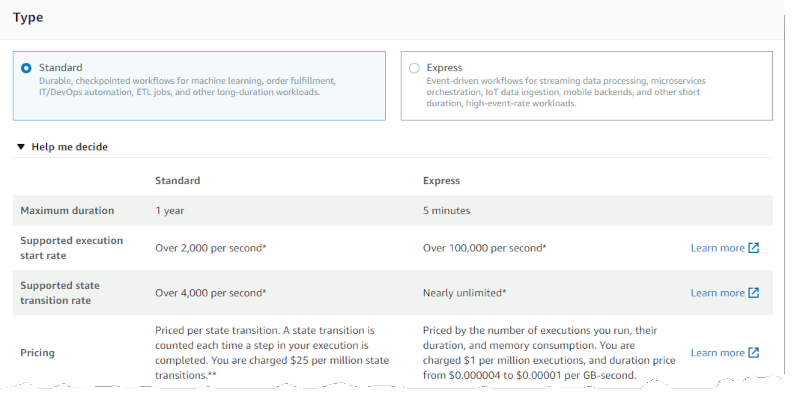
Naturally, I'll prefer nearly unlimited state transitions. Alas, I might want call-backs, which are only available in the "Standard" type. But at $25 per million state transitions it looks several orders of magnitude more expensive than paying $1 for a million complete executions (and $0.000004 to $0.00001 per GB-second, which I have no idea how many I'll incur). It would have been nice to be told if this decision is a one-way or a two-way door :-) (sources confirm it's indeed a one-way decision). For my trivial example, it's a toss-up. I'll go for "Standard".
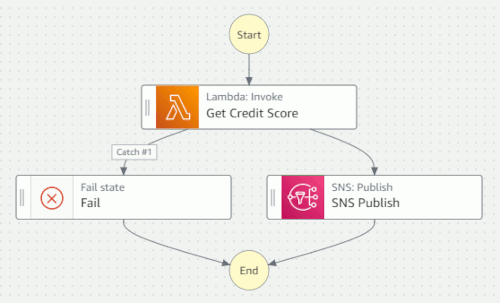
The first thing my flow needs to do is call the Credit Bureau, which I'll implement
as a AWS Lambda function (let's leave the async stuff for later). Encouraged by the
drag-and-drop UI, I easily inserted a Lambda:Invoke action into my flow. Not having created any Lambda function, however, meant that
I wasn't able to select one in the Workflow Studio. Step Functions punished my haste
by not saving my flow. Oops. This is a classic case of the tool assuming a specific
work sequence, which might not match reality. Luckily I only lost a state machine
with a single task.
Slightly smarter, I created the Lambda function first. The integrated editor makes creating and testing simple functions very easy. As our focus will be on the integration, my function is very simple: it validates the supplied SSN and returns random numbers for Credit score and history. To anticipate an asynchronous setup, my function also returns a caller-supplied request ID. In JavaScript, the function looks like this:
function getRandomInt(min, max) {
return min + Math.floor(Math.random() * (max-min));
}
exports.handler = async (event) => {
// TODO implement
const min_score = 300
const max_score = 900
var ssn_regex = new RegExp("^\\d{3}-\\d{2}-\\d{4}$");
if (ssn_regex.test(event.SSN)) {
return {
statusCode: 200,
request_id: event.RequestId,
body: {
SSN: event.SSN,
score: getRandomInt(min_score, max_score),
history: getRandomInt(1,30)
}
};
} else {
return {
statusCode: 400,
request_id: event.RequestId,
body: {
SSN: event.SSN
}
};
}
};
This is where I should likely be ZIP-ing up the function and storing it in an S3 bucket
for deployment via CloudFormation, but... the giant DEPLOY button is right in front of me. How do I often say: transformations that prescribe
one behavior and reward another are bound to fail. So I am not weak, I am simply the
victim of a misaligned incentive system!
Now we're ready to invoke the Loan Broker function with a Lambda:Invoke action, implementing a Content Enricher.
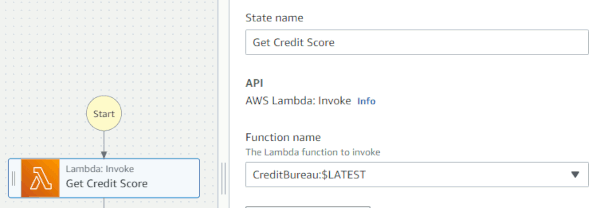
Now that was easy! However, data mapping turned out to be quite a bit trickier.
Step Functions allows you to transform data passed to an external entity as well as
the results that are returned. As described in the original Loan Broker Example, you can't expect other services to comply with your data format, so this is a very
useful feature. What's less useful is that those transformations are somewhat hidden
inside the Input and Output tabs of the editor. There you have to choose from a Payload expression, ResultSelector, ResultPath, Context object and a few other bits and pieces of magic that can be summoned through various
special character sequences. A Data Flow Simulator tool helps develop the needed JSonPath
expressions, but seems to require you to paste the JSON docs back and forth.
The Lambda:Invoke references a fixed parameter Payload that accepts JSON documents decorated with special expressions, for example to access
the Context Object via $$. We use the Context object's unique ID to provide a Correlation Identifier. An appended .$ indicates that an element is defined based on a JsonPath expression. But you likely
knew that...
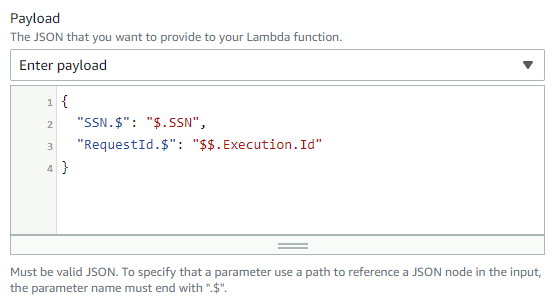
It's easy implemented but you'll be hard pressed to explain to anyone why those two lines took you 20 minutes to write. This is a common challenge I see with low-code tools, which defer the specification of "logic" to another language, JsonPath in this case, with limited editor support like auto-complete or syntax check. You end up writing less code, but it's not necessarily faster than using a regular IDE.
Processing the data returned by the Credit Bureau gets a bit more complicated. To Step Functions' defense I likely should have read the section Input and Output Processing under "How Step Functions works":
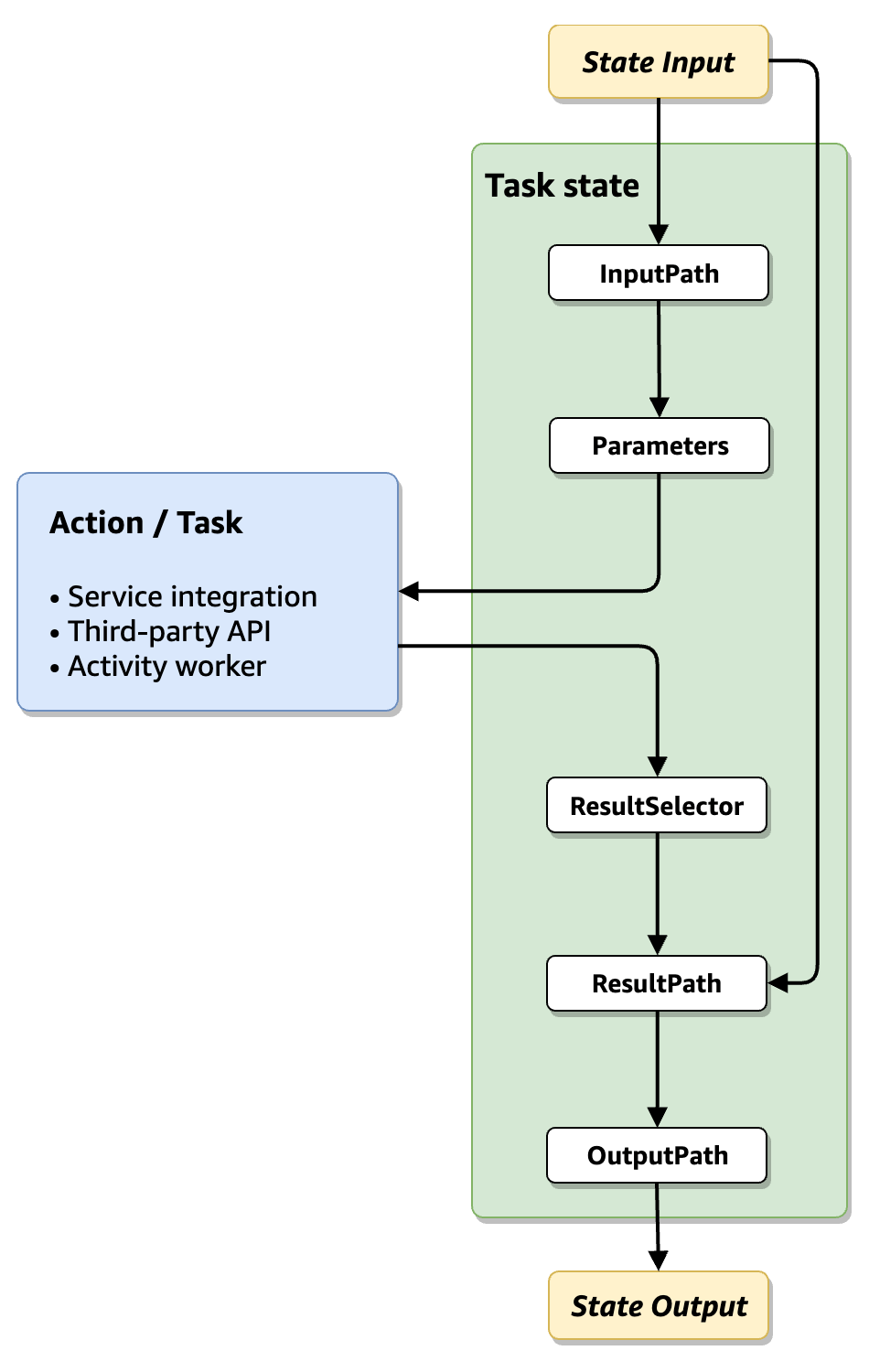
Drawn with EIP icons makes the intent a bit clearer ( reducing the blank space in favor of a larger font might have also helped):
The document state is sent to the external process after filtering and transforming. Returned data is also filtered and transformed before being enriched into the document state.
Sadly, the Workflow Studio UI gives little hint as to this underlying execution model. Also, I have to enter JsonPath expressions for document structures that I cannot easily see. I assume folks run the state machine partway, capture an example JSON document, then use the Data Flow Simulator to define the expressions and then paste them into the Workflow Studio.
We invoke the Credit Bureau synchronously, so we filter and transform the incoming
response via a ResultSelector expression and a ResultPath node.

One issue I ran into is that if one of the expected fields wasn't present, I'd be served a runtime error that I wasn't able to catch with the error "Catcher".
A "Retrier" setting allows Step Functions to automatically retry failed calls with an exponential back-off rate. I skipped this one for now as it's unlikely that a failed Credit Bureau invocation will success on a repeated attempt.
We're still missing the banks but it's a good time for a test run. No better place
for that than CloudShell. Via the command line you can easily fetch the ID for the Step Functions state machine
you defined (123456789 will be replaced by your account ID):
$ aws stepfunctions list-state-machines
{
"stateMachines": [
{
"stateMachineArn": "arn:aws:states:us-east-2:123456789:stateMachine:LoanBroker",
"name": "LoanBroker",
"type": "STANDARD",
"creationDate": "2021-07-11T06:39:34.552000+00:00"
}
]
}
Executing the state machine is also simple enough by supplying the state machine's
arn (arn's are like URLs for AWS resources; you can see they follow a quite logical format) and any input data. Make sure to supply a unique run name as that becomes part of
the execution's arn.
$ aws stepfunctions start-execution --name=myrun \
--state-machine-arn=arn:aws:states:us-east-2:1234567890:stateMachine:LoanBroker \
--input="{\"SSN\": \"123-45-6789\", \"Amount\": 500000, \"Term\": 30 }"
{
"executionArn": "arn:aws:states:us-east-2:1234567890:execution:LoanBroker:myrun",
"startDate": "2021-07-11T08:10:40.033000+00:00"
}
Looks good. Let's see how it did:
aws stepfunctions describe-execution \
--execution-arn=arn:aws:states:us-east-2:1234567890:execution:LoanBroker:myrun
{
"executionArn": "arn:aws:states:us-east-2:1234567890:execution:LoanBroker:myrun",
"stateMachineArn": "arn:aws:states:us-east-2:1234567890:stateMachine:LoanBroker",
"name": "myrun",
"status": "SUCCEEDED",
"startDate": "2021-07-11T08:10:40.033000+00:00",
"stopDate": "2021-07-11T08:10:40.453000+00:00",
"input": "{}",
"inputDetails": {
"included": true
},
"output": "{\"SSN\":\"123-45-6789\",\"Amount\":500000,\"Term\":30,\"Credit\":{\"Score\":524,\"History\":13}}",
"outputDetails": {
"included": true
}
}
If you don't fancy all the extras but just the data, you can append --query="output" to that command and pipe it into jq -r '. | fromjson'. That's a tiny portion of the magic that the AWS CLI can do for you. Voila:
{
"SSN": "123-45-6789",
"Amount": 500000,
"Term": 30,
"Credit": {
"Score": 524,
"History": 13
}
}
That's a nice JSON doc! After invoking the Credit Bureau our state machine contains the above data as the current document to be used in subsequent steps. You can also see this data in the pretty nice "Graph Inspector" ("graph" appears to be the prior name for the state machine) after the run. I quite like the structure of the AWS command line syntax - it's yet another handy feature that'll keep you off the noble path of Infrastructure-as-Declarative-Data-Structure-Config.
Getting the credit score is a great first step but what we're really here for is to get some loan quotes for our customers. We'll implement the banks as Lambda functions because the ease of deployment is simply unbeatable. The interaction with the banks is more complex than the Credit Bureau, though. We are looking to decouple the bank invocations from the loan broker so it's easy to add or remove banks. Also, we'll be using a Scatter-Gather pattern, so we need to aggregate the responses from multiple banks.
Just as in previous implementations, the major decision is whether to use a Recipient List, meaning the list of recipients is known to the Loan Broker or whether to use a Publish-Subscribe Channel. The latter pushes the message routing into the channel, which is generally preferred because it reduces coupling and better separates message routing from the endpoints. However, it also makes the Aggregator more complex as it won't lnow how many responses to expect.
Given the capabilities of Step Functions as an orchestrator, I'll build two separate implementations:
This version uses a Recipient List, meaning the Loan Broker first retrieves a list of banks to request quotes from (I took the liberty to place semantics ahead of product choice and thus intentionally departed from the all-icons-must-look-the-same template standard):
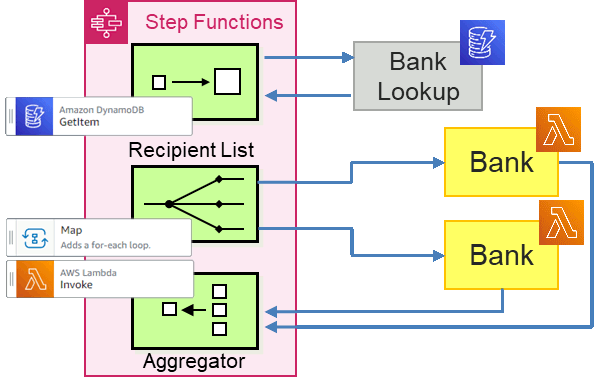
We'll retrieve the list of banks to be called from a DynamoDB item (perhaps a bit overkill but it's easy to fetch DynamoDB data from Step Functions) and subsequently sends those requests via direct Lambda invocations wrapped in a Map state. We'll simply aggregate the responses by concatenating them.
This version uses a Publish-Subscribe Channel, implemented via Amazon SNS, the Simple Notification Service.
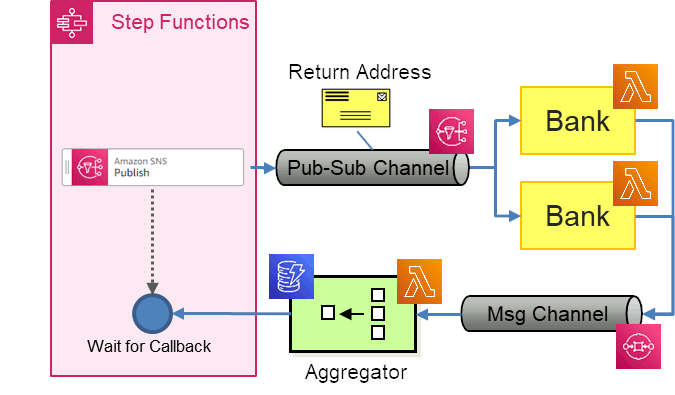
In this implementation we'll need a stand-alone Aggregator that can handle unknown numbers of incoming loan quote messages. I might be able to do it with a loop inside Step Functions as long as we are able to build a condition that terminates the loop. We'll cross that bridge (or rather the river) when we get there.
I'll implement and describe each option in upcoming posts.


 Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.
Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.