
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Find my posts on IT strategy, enterprise architecture, and digital transformation at ArchitectElevator.com.
Coupling is integration's magic word. Loose coupling affords the participants desirable properties like independent variability or operational resilience. However, as pointed out in a recent blog post, coupling isn't binary nor is it a single dimension. So it's time to apply our favorite architect maneuvres—seeing more dimensions and seeing shades of gray—to coupling.
Like most architecture concepts (and the concept of architecture itself), finding a universally agreed-upon definition of coupling isn't easy. I fall back to my description from many years ago:
Coupling describes the independent variability of connected systems, i.e., whether a change in System A affects System B. If it does, A and B are coupled.
This definition places coupling at the center of change propagation, meaning if one component changes, does that change affect other components? Change comes in many forms, for example, a change in requirements, a change in scale, or a change in component latency or availability. Systems that are (more) tightly coupled tend to be brittle: local changes trickle through the system. Those changes can be functional, meaning the system is difficult (and risky) to change. They can also be operational changes like the outage of one component. If other components are temporally coupled to this component, a local issue can drag the entire system down. We call such a system brittle, meaning it isn't resilient because it doesn't absorb disturbance.
I have long resented the idea of coupling being regarded as some form of bit that's either set or not, meaning something is coupled or magically decoupled. As computer folks, we like binary things, but unfortunately coupling (like most architecture considerations) isn't one of them. My oldest and still favorite quote aptly takes the notion of coupling being an on/off switch to the extreme by providing this clever advice for setting the coupling bit to "false":
How do you make two systems loosely coupled? Don't connect them. (David Orchard)
So, the objective can't be to make everything loosely coupled but rather to understand the nuance of coupling and the design trade-offs that are involved. For example, for functional changes, if you have full control over all system components, good test coverage, and high levels of automation, coupling may not be a big issue. For example, method names are tightly coupled, but most modern IDEs support a rename method refactoring, which allows us to overcome the change propagation with a single (right) button click.
The insight that an acceptable amount of coupling is connected to the level of control leads us to my basic theorem of coupling:
The appropriate level of coupling depends on the level of control that you have over the endpoints.
Not only is coupling non-binary, it's also not one-dimensional. Whether a change propagates through the system depends on the type of change. So, we amend our definition:
Coupling describes the independent variability of connected systems, i.e., whether a change in System A affects System B. If it does, A and B are coupled with respect to this change.
For example, a location-dependent solution requires an update to each sender when a recipient changes location (such as a new URL or IP address). In other words, sender and receiver are coupled with respect to location, or location coupled in short. It's easy to see that even this single dimension has many nuances. For example, using URLs or hostnames instead of IP addresses gives the sender and receiver more variability, but it's a sliding scale. A hostname doesn't cover a server failure as the new server likely has a different name. Also, the solution might use a load balancer that can decouple single server outages but not the loss of an entire availability zone.
I first captured the notion of breaking coupling down into multiple dimensions in the introduction for Conversation Patterns, which indicates the last update to be from January 2017. A quick check into the git repo revealed that this text is at least from 2015
The same idea found its way into a slide deck on resilience at Yow! 2016:

Some good ideas apparently take time to fully bake, so I evolved it for my GOTO EDA Day Keynote and my re:Invent talk on distributed systems in 2022 (the number of facets increased from 5 to 8 over the course of nine years):

Avid readers will recognize the following slide from a blog post on my Architect Elevator site.
It's time to give each dimension a closer look:
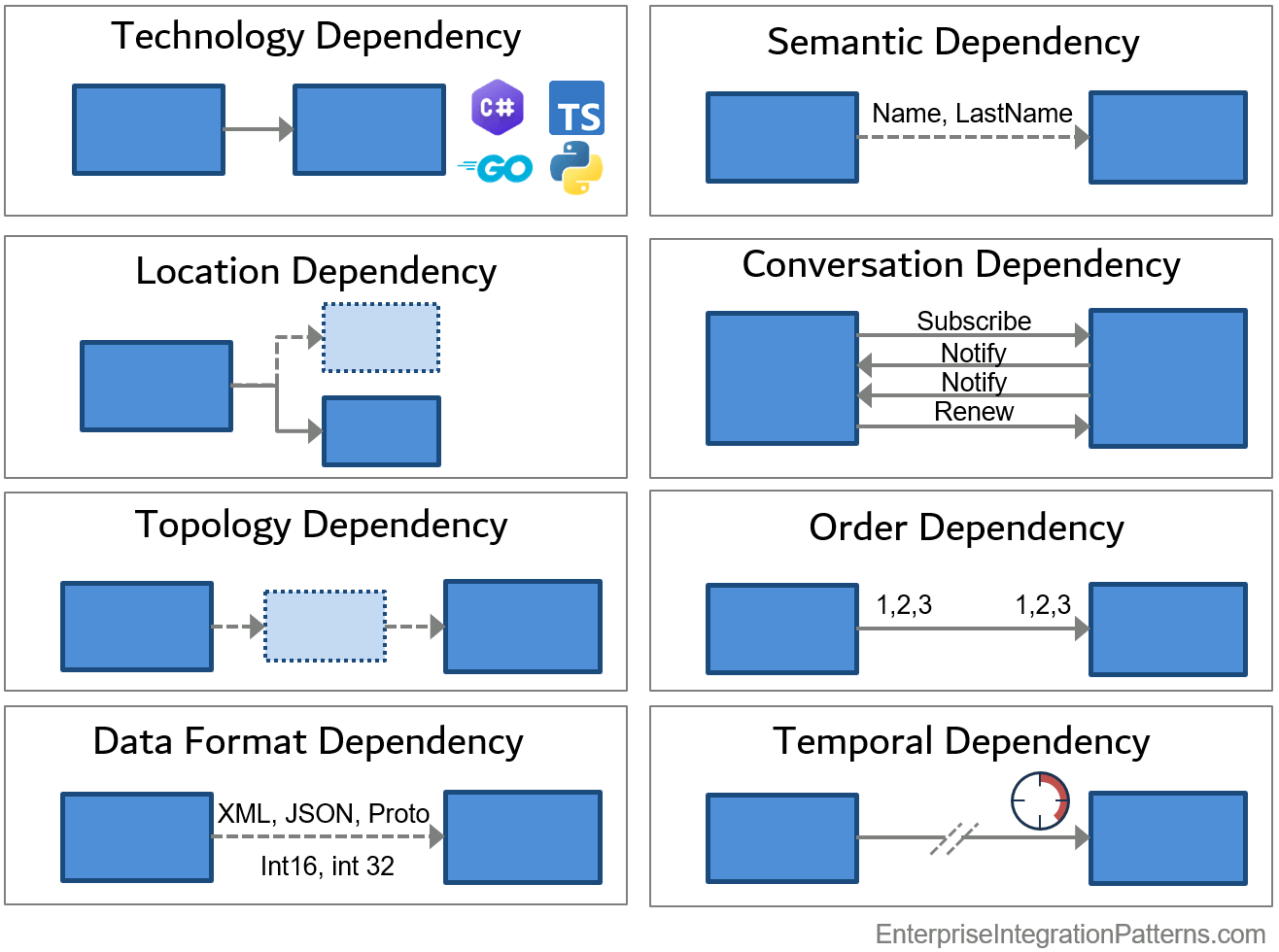
This dependency exists when communicating systems depend on each other's implementation technology. Such dependencies are reflected in the protocol, naming schemes, or data types. For example, data encoding can be impacted by the underlying operating system or processor architecture, such as a big-endian or small-endian encoding of integer numbers. Accordingly, if one component changes the processor architecture, other components would have to be updated unless this aspect is decoupled.
Protocols built into frameworks or libraries, such as JMS, DCOM, Java RMI, Jini, etc. tend to trade off technology dependency for efficiency, which—as we learned above— is a reasonable choice if you control the technology of all participating systems. Still, it's not that they are tightly coupled in all regards. For example, DCOM works across different languages like C++ or C#.
To allow systems to communicate with one another, they must agree on some common addressing scheme. A local method call does so by the method name or the memory address for compiled languages under the assumption that the target resides in the same virtual machine as the sender. RPC-based distributed systems tend to use IP addresses, host names, or URLs. Message-oriented systems specify a destination via the name of a Message Channel, topic hierarchies, or a shared blackboard tuple. Each of these choices can absorb certain degrees of change without propagating it to other participants, meaning they are loosely coupled with to that change. A simplified heuristic implies that logical addressing is more change-tolerant than physical addressing. Although that is true in principle, "logical" and "physical" are relative to the respective layer in the communications stack. For example, IP addresses are logical when compared to MAC addresses with the mapping managed by a DHCP server, which plays the role of the Consult Directory conversation pattern.
Once again going back a decade-and-a-half, a slide from a presentation about Event-Driven Architectures from 2007 elaborates on different naming schemes and their levels of coupling:
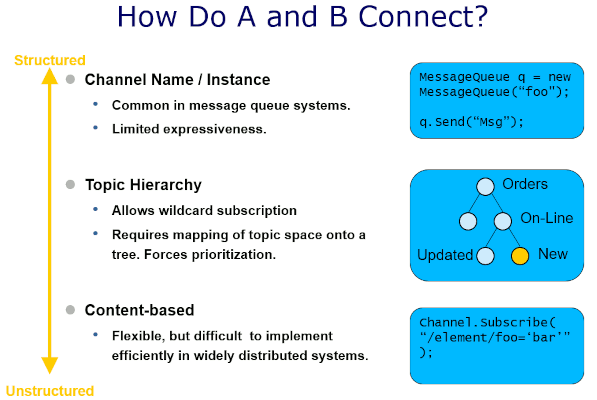
Note how the slide cleverly avoids suggesting a single dimension of coupling, but rather presents the location dependency on a spectrum of more or less structured. Using channel names is structured, because sender and receiver must agree on a common name in order to connect to one another. Topics, which are frequently used with Publish-Subscribe Channels, provide subscribers with the ability to subscribe to different nodes in a hierarchy. This way, they have more control over the messages they receive. Some systems have prefix matching for string fields, which can be used to emulate a topic hiararchy (by matching for "A.B.*" for example). The least structured form allows recipients to filter messages by data fields. In this case, the sender doesn't need to specify any particular data for matching with recipients but. Instead, this responsiblity is pushed entirely to the recipient.
The need for sender and receiver to agree on a common address can also be eliminated by using explicit composition via an "Assembler" component. Sender and receiver have no knowledge of each other because they are connected by a third party.
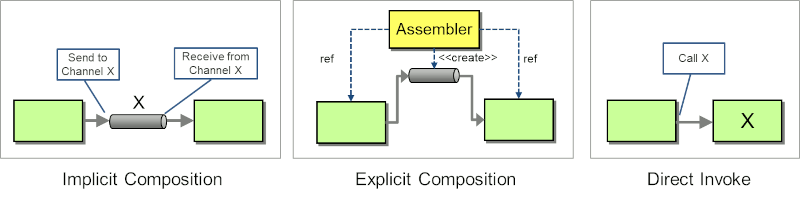
As expected, there is no free lunch. In the pursuit of total location decoupling, you are shifting the change dependency to a special kind of "god class", which can become a maintenance bottleneck.
Although this single dimension of coupling isn't linear, we can roughly depict the progression of location coupling from tight to loose as follows:
Hard-coded addresses → Host Names / URLs → Logical Names → Topics → Content → Explicit Composition
The Reactive principles highlight the importance of location decoupling for operational resilience. The principle of Decoupling Space states:
Spatial decoupling enables replication, which ultimately increases the resilience of the system and availability. By running multiple instances of a component, these instances can share the load. Thanks to location transparency, the rest of the system does not need to know where these instances are located.
A common challenge of location decoupling is that logical abstractions cannot hide physical properties. For example, if the system is location decoupled, but the new component is further away and carries more latency, then there is physical coupling, which might affect run-time characteristics.
As highlighted in the presentation from 2016, location independence affords composability: if one component doesn't make location assumptions about the components it is interacting with, another component such as an intermediary can take its place without any changes to the sender. This special case leads us to the next dimension:
Topology in this context indicates the arrangement of the application components, akin to a Network Tolopogy. Swapping out one element for another or moving it to a different location (without changing the interconnections) does not alter the topology because the graph of connections didn't change. However, adding an intermediary or an additional recipient does alter the topology because a node was added and connections changed.
When component A regularly communicates with component B, inserting an intermediary C between A and B implies a topology change. Likewise, if A sends messages to B and C, adding a new recipient D is a topology change:
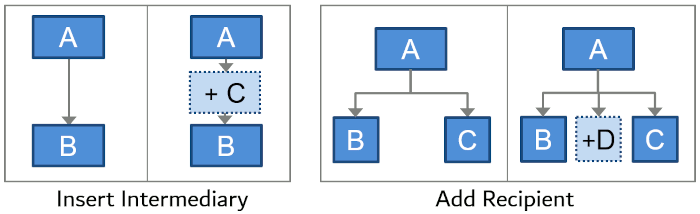
Inserting an intermediary is a popular way to reduce other forms of coupling. If A sends messages to B, but B changes the expected message format (for example, renames a field), you would have to change A as well (because they are coupled with respect to data format). However, in some cases you may not have control over A, for example, because it is a third-party application. In those cases, you can insert a Message Translator between A and B that takes care of the difference in data format. This new element now decouples A and B, at the cost of an additional element. However, for this to work, A and B must be topology decoupled, meaning that inserting the intermediary doesn't require any change to A. That could be because A emits events or sends messages to a logical channel instead of to B directly. We notice that the dimensions of coupling aren't entirely independent, but that you can use one form of decoupling (topology) to overcome another form of coupling (data format).
Most integration data formats, such as CSV files, XML, or JSON are designed to reduce or eliminate technology dependency, such as big or small endian or terminating strings with a zero or not. However, data encoding also carries many nuances that in turn imply coupling. An integer number may consist of 32 bits on one system and 64 bits on another. Character strings might consist of 8-bit ASCII characters, EBCDIC values, or UNICODE characters. Therefore, both systems have to agree on a common data representation scheme. Some encodings, like fixed format EDI records, rely on a particular order of parameters, which breaks when adding or removing data items. "Tagged" formats such as name-value pairs, XML, or JSON documents loosen up such constraints and reduce coupling.
The two levels that I lumped into one category have slightly different "change triggers": a data format change refers to a new, renamed, or repositioned field. For example, JSON will tolerate a position change or a field addition whereas EDI records will not. Data type dependency relates to the encoding of fields, which can include aspects such as optional fields or whether missing fields are interpreted the same as a present, but empty field. Such seeming nuances have broken numerous integrations in subtle ways!
Most integration tools have provisions to lower this form of coupling by providing common transport and encodings plus Message Translators to absorb differences in field names or document structure.
Data format coupling can depend on the endpoint implementation. If a message consumer iterates over the nodes of an XML document, expecting a specific order (perhaps a poor idea, but I am sure it happens), it will not be tolerant of order changes. In contrast, a consumer that uses XPath expressions to extract fields will be. As a result, it's not a sufficient contract to just state the data format; you also need to document assumptions or levels of change that must be tolerated by the endpoints.
At Google we used Protocol Buffers to describe the contract between services. Protocol
Buffers specify the data format using an IDL (Interface Definition Language), from
which endpoints can be generated for various languages. To make data formats backward
compatible, new fields were routinely tagged as optional even though they were required by the receiver. The result was that coupling shifted
from the IDL to the endpoint implementation.
Data format coupling has a nasty habit of getting in the way of other forms of decoupling. For example, components may be topology decoupled, but changing the topology may impact the data format, essentially voiding the decoupling.
Semantic coupling is the "next level up" from data formats and types, both from a layer communications model as well as from a complexity point-of-view. Having a UTF-8 encoded string with a well-defined field name doesn't mean two systems have the same interpretation of its content. The same can happen for systems that break down data into geographic regions: one may use ZIP codes, another one area codes, and a third one segments like Midwest. One system reports data weekly, another monthly, and a third one by 30-day intervals.
Semantic dependencies and mismatches are notoriously difficult to overcome with format-oriented integration tools. For example, area code boundaries don't line up with ZIP code boundaries, leaving you very little for a conversion from one to the other. In many other cases, the real meaning of fields may be buried in a legacy system or long forgotten.
System interaction isn't done by sending one message or invoking a simple API. Many business interactions involve acknowledgment, confirmation, retries, timeouts, cancellations, and compensating actions—in the real world as much as in system integration (I could add Sagas here just to tick off Udi ;-) ). Assumptions about the order of messages and changes thereof constitute a major dimension of dependency and coupling.
For example, if your favorite coffee shop asks you for payment before delivering the drink, is that specified in the protocol or just coincidence? If the consumer assumes this order, then the two parties are coupled with regard to a change in message order.
The relationship between conversations and coupling is a key force behind Conversation Patterns. One could write an entire book about it ;-) Understanding conversation coupling is often hindered by the fact that the conversation can span different systems and isn't documented in a central place.
If you feel that your interaction is simple and there isn't much conversation going on, be aware that a retry is also a conversation and is bound by its rules and assumptions: are retries allowed? is the number of retries unbounded? Is the recipient idempotent? how should the requestor handle duplicate responses resulting from overeager retries?
Systems may make assumptions about message order. If those assumptions change, or a message producer changes the order of messages, subsequent systems may have to change—another form of coupling! Messages that contain unique time stamps or unique keys for insertion into a data store tend to be tolerant towards out-of-order delivery, caused by the sender, the Message Channel, or intermediaries. In-order delivery makes building systems easier but can hurt throughput. As I often state:
Message endpoints usually prefer in-order delivery, but messages don't! Drawing an analogy with a supermarket check-out line, imagine a person who is extremely slow to check out and holds up everyone else in the queue. Everyone wishes for out-of-order processing!
Order generally has to be defined relative to a scope. A Messaging System may preserve order, but a set of Competing Consumers process messages out of order nevertheless.
One of my favorite ordering stories is from my Silicon Valley days where one of our best developers built a message-based integration between multiple systems to replace a brittle Database Integration. He initially felt that this task was somewhat beneath him until he discovered a race condition in the original system. Asking the users for the desired behavior yielded no results as no one was aware of this bug. Oh, the joys of integration!
If systems communicate synchronously, i.e., the requestor waits for the provider's response, the requestor is temporally dependent on the provider: a slow provider causes the requestor to also become slow. Worse yet, if the provider is unavailable or unreachable, the requesting system is also rendered unavailable. Asynchronous messaging solutions cannot magically make an unavailable system available, but they can temporally decouple systems by having the requestor not expect an immediate response. Alternatively, the requestor could implement graceful degradation, so that it remains operational, although perhaps with limited features.
A popular saying of mine is that the purpose of a model is to answer a question or help you make a better decision. So, the proposed model of coupling dimensions should pass this test, right? Interestingly, I extracted this post from another one that got too long. That means, this model came to be so that It helps me have a better discussion about the following topics:
The first one is to put more meaning behind blanket statements like event-driven architectures are loosely coupled. Architects should as, loosely coupled in which regard? Compared to what? Why does it matter? Having this model and vocabulary allows us to debunk such oversimplified statements. My learning while writing this up was the following:
Once you describe the real architecture forces behind blanket pseudo-architecture statements, you may run out of space.
That's why I split that post into two parts, this being part one.
The model also helps us discover a dangerous form of coupling: things look decoupled at one level, but are actually coupled due to another type of coupling. I observed this in cloud-based serverless applications:
Serverless integration services appear to be topology decoupled thanks to logical resource identifiers like ARNs on AWS. But it turns out that message formats are dependent on the source. Therefore, inserting a message queue or changing the data source in a serverless, event-driven application changes the message and forces downstream consumers to change—topology coupling!
Such applications look recomposable at the surface but are topology-coupled via the data format. That's worth a blog post as well!
Share: Tweet
Follow:
Follow @ghohpe
![]() SUBSCRIBE TO FEED
SUBSCRIBE TO FEED
More On: INTEGRATION CLOUD EVENTS ALL RAMBLINGS


 Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.
Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.