
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Find my posts on IT strategy, enterprise architecture, and digital transformation at ArchitectElevator.com.
Mashups pull data from different sources, aggregate and transform the data to be used in different contexts. EAI solutions pull data from different sources, aggregate and transform the data to be used in different contexts. Huh?
The Internet has come a long way, from static HTML pages to online shopping pages and photo albums to community-driven sites like MySpace, Digg, del.icio.us, Flickr, Twitter and so on. The newer sites fall into the so-called Web 2.0 category, a term coined by Tim O'Reilly back in 2003 (time flies!). While it is difficult to define Web 2.0 in precise terms, this class of applications usually lives off a network effect created by user participation, for example users tagging photos or sharing their bookmarks. They also use the Web as a platform to retrieve and share data, often from multiple sites. These mashups use lightweight programming models such as JavaScript to pull data together and present them to the user in a meaningful way. For example, one such mashup pulls a feed of suitable apartments from a listing site and plots them on Google Maps. Don't be left behind in Web 1.0!
In a previous post I promised to talk a bit more on Google products, especially now that Google has a variety of offerings in the Web 2.0 space. As great as maps are, the Maps API is now one of 34 (!) public Google API's and developer tools. Since I've been playing with Mashups recently, what would be a better fit than Google Mashup Editor (GME)? GME provides a browser based development environment that allows developers to create HTML pages, which incorporate data from external sources. My GME tutorial on Google Code describes how to build a simple GME application, which uses data from my public Google speaking calendar (the calendar is a little sparse right now as I am planning my next round of conference appearances). Google calendar data is available as an Atom Feed, which can be read by GME. My GME application calls the Google Maps API to enrich the feed with longitude and latitude data based on the conference location. Finally, it plots the results on a map. Not earth shattering, but trying to build this type of application 5 years ago before the advent of geocoding, RSS, Atom, and Google maps would been very time consuming at best. The presence of standard protocols and powerful tools make this type of integration relatively easy.
Did I say "integration"? Yes, you heard correctly. Nowadays the term "EAI" is certainly more uncool than anything Web 1.0 but the problems of integration have not gone away. Let's look at the GME application I just described from a higher level of abstraction, let's say at the level of integration patterns:
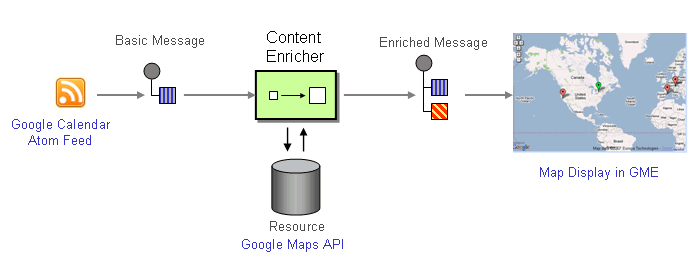
Looking at the application from this angle, the solution is made up from a data source (the calendar feed), a Content Enricher, which access a resource (Google's geocoding database), and a message consumer (the GME application). The tutorial uses the Google Maps JavaScript API to perform the geo lookup: every time the user selects an entry from the list of conferences, GME invokes a short JavaScript to perform the geo lookup. This implementation ties the Content Enricher aspect of the solution rather tightly to the display module. Obviously, tight coupling is frowned upon in integration land. So let's change it.
The integration patterns help us decompose the behavior of our solution into individual patterns. Using the Pipes-and-Filters style, we can implement each pattern as its own component and compose the solution from the individual pieces. The composability of the pipes-and-filters approach is one of its biggest strengths and hinges on the availability of a universal message channel. As we all know, the Internet is not message-oriented (although I argued before that it can be considered event-driven), but not all is lost. The most common integration point on the Web is XML over HTTP, especially when using standard formats like RSS. So could we use RSS as our message channel and compose the solution from independent components? Last time I showed how to use Yahoo! Pipes to extract XML data from Amazon's e-Commerce Service and convert it into an RSS feed. Pipes can do a lot more, including geocoding of an incoming RSS feed. In this role Pipes enriches the data stream with geo data, i.e. longitude and latitude, and makes the enriched stream available as an RSS feed, our universal integration point. Naturally, GME applications read geo-enriched RSS feeds and display the data on a map without even a single line of code. The new solution looks as follows (sorry for the 90 degree rotation):

My new tutorial on Google Mashup Editor and Yahoo! Pipes describes how to build this solution step-by-step.
Using Pipes in this role reminds me of the VETO pattern: Validate, Extract, Transform Operate, which is commonly used in EAI and ESB solutions (e.g., see Dave Chappell's description of the pattern ). It sounds like a number of our friends from the EAI world are still useful in the world of Web 2.0 and mashups.
In my post about Mashup Camp I speculated that the difference between mashups and composite applications is more about the approach than the technology, so it is not surprising that some of the same patterns and techniques seem familiar. This fact appears to be confirmed by vendors with extensive integration and ETL experience now dabbling in the mashup space (more about that next time). While we do not want to sound like the CORBA people in an SOA world ("we built all that 10 years ago!"), it does mean that some of the old challenges are likely to still haunt us. For example, token and ID management can already become a challenge for mashups. Semantic mismatches and incompatible data formats are a staple of data integration and are not likely to vanish.
However, I think we learned a few things in the meantime. Because integration is difficult, mashups set the expectations lower and are generally less ambitious. They provide small, high-value point solutions as opposed to trying to achieve enterprise-wide integration nirvana. Moreover, after realizing that syntactic schema definitions à la WSDL solve only a very small portion of the semantic mismatch issues, mashups put the whole notion if schema aside and just look at an example message. Yahoo! Pipes makes this very clear when you use the "Rename" module. This module is the equivalent of the omnipresent EAI transformation editor. Rather than requiring a schema, the module samples the incoming stream and gives you a selection of all fields it saw. Is the field required or optional, a string or a number? Pipes does not care much because it does not have to. Does this mean schemas and data formats are a dumb idea? No, if you are building a B2B integration with your business partners a rigid definition of all message formats and protocols (beyond schema) is an excellent idea (hello, RosettaNet). Tools like Pipes highlight that the schema approach is a pretty big hammer and you can get pretty far with a much smaller hammer, that is also easier to carry around.
The IT world is known for its short memory (and attention span). So let's remember what we learned in EAI and not reinvent everything from scratch. Repackaging some of the old stuff can be fun and gets attention. In the EAI world I would have never written a tutorial explaining how to add two data fields to a message stream...


 Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.
Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.