
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Find my posts on IT strategy, enterprise architecture, and digital transformation at ArchitectElevator.com.
Our client had a rather lengthy stored procedure to aggregate values across a series of data records and compute "scores" from these aggregates using various look-up tables. The records in the database represent essentially a collection of user input over time. Our client was facing two main issues: first, the stored procedure was becoming unwieldy due to new requirements for the support of new types of products and scores. Second, the batch-orientation of the stored procedure caused response times to be uncomfortably slow. While the data access part of the procedure was naturally efficient, more and more business logic inside the procedure started to bog down the database server.
We addressed the first problem by converting from PL/SQL to Java code, which allowed us to structure the solution using object-oriented constructs. We targeted the second problem by processing user events as they occur instead of waiting for all events to be collected first before starting to compute aggregated values. In order to allow for future flexibility we developed a set of self-contained components, called "calculators", that we could connect to one another via event channels. Each calculator would subscribe to a set of relevant event types and in response publish events of other types. This this loosely coupled architecture enabled us to compose new solutions from existing calculators quite easily, sorta like Lego.
In order to realize this architecture we had to build an event channel and a way for calculators to publish events or subscribe to them. We chose to build the solution from scratch because our requirements were in fact quite simple. For example, we wanted our architecture to be amenable to distribution and asynchrony but for our initial channel a synchronous single-JVM implementation was sufficient. On a second look, we could have benefited from something like ActiveMQ, a messaging framework that supports intra-VM channels. Also, some of the J2SE5 features in the java.util.concurrent package as well as generics could have come in handy, but the GA release was just a few months too late for us. BTW, I just saw there the is a Back-port to 1.4 for the concurrency package, which is great.
Anyway, we set out to build the event channel from scratch and it turned out not to be very much code. The channel interface is in fact very trivial:
public interface Channel {
public void send(Event event);
public void subscribe(EventRecipient recipient, Class eventClass);
}
This interface sure seems simple enough to be implemented in a variety of messaging frameworks. Subscriptions are based on the type (class) of the event (more about this soon). One important property, however, is not apparent in the interface: our channels are Publish-Subscribe Channels. This implies that many subscribers can subscribe to the same channel and each receive a copy of the same message.
One important part is still missing in this messaging layer: subscribers need to be notified when an event occurs. We wanted all our subscribers to be strictly event-driven, i.e. subscribers do not have to poll for events but instead are actively invoked whenever an event occurred. With our solution, receiving messages became as simple as implementing a method of name onEvent with a parameter of type Event, or a subtype thereof. Whenever an event of the subscribed type is published to the channel, the channel will directly invoke the onEvent method of all appropriate subscribers. In our simple implementation, this invocation occurs via reflection.
With all this in mind, to build a very simple subscriber here is all you have to do:
public class DebugCalculator {
public DebugCalculator (Channel channel) {
channel.subscribe(this, Event.class);
}
public void onEvent(Event event) {
System.out.println("event = " + event);
}
}
It might be impractical to have to create a new channel for each type of event so we allow subscribers to subscribe to specific types of events. A subscriber will only receive events of the type it subscribed to or subtypes thereof. Essentially, we created a publish-subscribe topic hierarchy based on Java classes. Most publish-subscribe messaging systems specify topic hierarchies in a specific textual notation, such as topic.subtopic.subsubtopic. A subscriber can then choose to subscribe to topic.* to receive all messages for this topic or any subtopic. As a side note, JMS does not specify this behavior for its publish-subscribe topics, but essentially all JMS providers support it with slightly varying syntax.
In our world, such a topic hierarchy would be represented as a class hierarchy like the following:
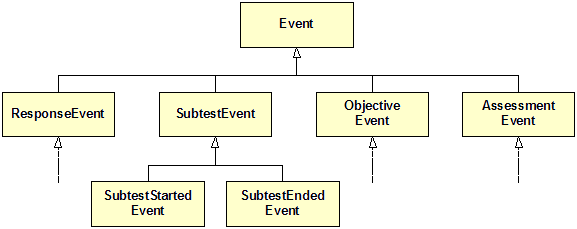
A subscriber who subscribes to the type Event would receive all events while a subscriber who subscribes to SubtestEvent would only receive events of type SubtestEvent, SubtestStartedEvent and SubtestEndedEvent. This feature makes it very convenient for calculators to subscribe to multiple topics at once. For example, the DebugCalculator shown above simply subscribes to all events by invoking subscribe with Event.class. Even if new event types are added, the DebugCalculator will receive the new types just as well. At the same time the publish-subscribe property of the channel ensures that this debug calculator does not affect any of the existing message flow. We could say that Publish-Subscribe Channels are side-effect free in regards to adding new subscribers. Programming this way has a very aspect-like flavor as you can easily apply processing to whole classes (pun intended) of events.
Our event channel deals with a second type of hierarchy though, which is somewhat unique to the way we invoke event recipients. We wanted to avoid the typical if (... instanceof ...) goo that often plagues message-driven systems that deal with multiple event types. Therefore, we made our channel smart enough to invoke the most specific (i.e. deepest subclass) implementation of the onEvent method in the recipient. The channel performs that evaluation for each event. This behavior becomes clear with a simple example:
class SubEvent1 extends Event {}
class SubEvent2 extends Event {}
class SubScribeToAll {
public SubScribeToAll {
channel.subscribe(Event.class);
}
public void onEvent (Event e) {}
public void onEvent (SubEvent1 se) {}
}
This class subscribes to the base type Event. As a result, it will receive events of type Event, SubEvent1, and SubEvent2. According to our implementation, for each event of type Event (excluding subclasses), the method onEvent(Event) is invoked. For events of type SubEvent1, the method onEvent(SubEvent1) is invoked because this is the most specific onEvent methods. On the other hand, for events of type SubEvent2, onEvent(Event) is called because that is the most specific method that matches type SubEvent2.
This feature makes event dispatching inside event receivers almost trivially simple as demonstrated by the DebugCalculator.
Originally I was going to dive into the implementation details of the channel but I think I'll postpone that into a separate posting. If you are of the impatient type, Binkley's Blog gives you a good idea. He also converted the channel to J2SE5.0 using generics.
i was particularly interesting to see what kind of common patterns would emerge given our basic architectural style. I intentionally held back on giving everybody a copy of my book and say "Hey, use these patterns!". In the end I was even more pleasantly surprised that the calculators essentially fell into a handful of pattern categories in my book (see figure).
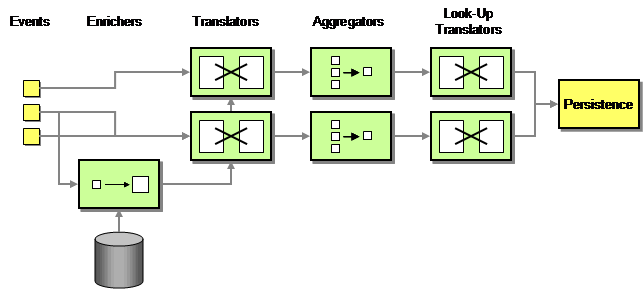
The first "bank" of calculators acts as Enrichers. These calculators access the database to retrieve context data that is required to compute the scores. The Enrichers publish the context data to the event channel. The next stage is a set of Message Translators that use both the context data and the event data to compute basic scores. These basic scores are then republished as events, which are consumed by a bank of Aggregators. The Aggregators republish aggregated data to be transformed by another set of transformers. It was interesting to observe that this staged architecture was not clear at the beginning but evolved over time.
One important design decision was how small or how big to make the calculators. Smaller calculators would improve composability and testability but could also cause unnecessary overhead and complexity. It turned out that the message channel overhead was quite insignificant. Therefore, we decided to make the calculators as small and as generic as we could. This drastically improved testability. For example, a score calculator would not retrieve its own context data from the database but instead subscribe to an event from a separate Enricher. This allowed us to feed mock context data to the calculator during unit tests and kept these tests database independent. This realization prompted my earlier posting on Inversion of Control.
However, having many calculators also caused some pain. The number of event types exploded as the event type was our only routing mechanism. This was partly due to the fact that we sent all events on a single channel. Using different channels for different stages would have made life a little simpler. Also, having multiple inheritance could have been helpful. We briefly considered routing events based on multiple marker interfaces attached to events but the production deadline kept us from exploring this option further.
One of the coolest features this architecture enabled was the ability to replay events. None of the intermediate calculators persist any state. We do, however, persist each original user event in the database (the exiting application already did this for us). This allowed us to largely ignore transactions, which can be painful in event-driven environments. Also, in the event of failure we could simple re-instantiate all calculators and replay all events in the user event log. All calculators would then rebuild their state based on the original message stream. This feature came in very handy.
What else would we like to do if time permits? I would definitely recommend a Visualization engine like this one. Generating HTML like my good old TibDoc would also be a great troubleshooting tool (on of these days I should post sample output of that tool...)
The next logical step would be to replace the synchronous intra-jvm channel implementation with "real" JMS channels. This would carry more messaging overhead but allows us to scale out enormously. It would be interesting to see whether it is better to cluster certain types of calculators on one set of machines (SEDA style) or run a whole calculator chain on each machine and load balance (with session stickiness) across them. My intuition tells me SEDA but since out calculators are small the messaging overhead might be prohibitive. As with any performance tuning only a real experiment will tell.
Next time: the channel implementation in Java.


 Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.
Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.