
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Find my posts on IT strategy, enterprise architecture, and digital transformation at ArchitectElevator.com.
Everyone seems to hail the benefits of building loosely coupled systems. I have my own opinions on coupling but that'll have to wait until another rambling. For now, let's agree that loosely coupled systems are systems that make fewer assumptions about each other. A loosely coupled interaction is desirable in those cases where individual components should not depend too much on each other, for example because they are part of different applications or organizations.
While loose coupling can be a desirable architectural principle it also has drawbacks. Loosely coupled architectures can quickly turn into what Martin Fowler calls An Architect's Dream - A Developer's Nightmare, alluding to the fact that loosely coupled systems are inherently difficult to test and debug. For example, if a solution uses message-based integration, a component may simply write messages to a channel or read messages from a channel without knowing which component sits at the other end of that channel. This architecture allows for great flexibility in composing these types of solutions from reusable components. However, if we face a performance bottleneck or detect invalid messages it would be tremendously useful to know where messages actually come from and where they are headed.
I am a big fan of visual representation of systems. Sometimes you simply need the literal "big picture" to see what is going on. Unfortunately, most visual representations these days are linked to the term modeling as in model-driven architecture. This type of modeling suggest that you can design the system visually using some form of Doodleware and then more or less generate the code for the running system. I am not the only one to have mixed feelings about this approach, especially in a distributed an loosely coupled system that is will evolve over time. Modeling such a system in a single tool seems to assume that you have a clear understanding of how the individual pieces are going to interact. I feel that in a loosely coupled integration of multiple pieces this is typically not the case. In fact, not knowing how the system will evolve is one of the key reasons for us to build loosely coupling solutions. In a loosely coupled solution, components should be able to subscribe to message feeds without affecting the sender of the messages or the integrity of the system. It seems like loosely coupled systems encourage some form of controlled "anarchy" to allow the overall system to evolve in a natural manner. Most model-driven approaches, on the other hand, take more of a "big brother" stance where we want to design the whole world in one run from the top down.
Likening a loosely coupled system to "anarchy" might be a bit strong but the important aspect is that uncontrolled variability is supported and to some extend encouraged. How then, do we keep tabs on what is going on in the system? A visual representation of the system is certainly useful, especially if we deal with a system that is asynchronous and concurrent by nature. If we cannot design the whole system from the top down how can we get such a visual representation? We should harvest it from the actual system! This way we get an accurate depiction of the system without imposing a certain structure onto it. I call this technique bottom-up visualization to set it apart from top-down modeling approaches a la MDA. For example, we can track which message channel each component is publishing or subscribing to. We can then use this information to create a message flow graph that depicts how information flows from component to component.
These kinds of visualization tools are receiving quite a bit of attention these days. For example, a key component in the next generation of Microsoft's Visual Studio called Whitehorse can inspect Web references from one project to another and display the resulting relationships in a visual editor. In Microsoft's case this editor also allows the user to add or remove dependencies, i.e. it is "roundtrippable".
The first step to visualizing dependencies between systems is to determine the dependencies in the first place. This can be accomplished in a number of ways, such as:
A number of packaged EAI tools, such as TIBCO, feature a Metadata Repository. This repository is the source for configuration information for all components. Whenever a component is supposed to subscribe to a specific channel the channel name is actually stored inside the repository via a configuration tool. When the component starts up, it retrieves the actual channel name from a specified path in the repository. Having such a central repository makes it very easy to figure out all communication between components, that is, as long as all components use the repository as opposed to hard-coded channel names (for example, see my TibDoc Project. However, this approach is limited to detecting static communication between components. For example, if a component specifies a Return Address at run-time, the communication dependency established via the reply message would not be contained in the metadata repository and would therefore not be displayed.
In the absence of a metadata repository we can capture all messages that flow through the system in a central Message Store. This approach is dynamic in nature, that is, it observers a running system. In contrast, inspecting the Metadata Repository is considered static analysis because the analysis only involves design-time artifacts. Based on the message header we can then figure out which component sends message to which other component. Since we inspect a running system we can also get data on the message volume. The main drawback of using a message store is the high volume of message data sent to the message store. If all we want to do is visualize publication and subscriptions this approach can be overkill because it is likely that a component sends many message instances to the same channel.
To be more efficient we should only track subscription and publication requests. Whenever a component obtains a channel reference for publication or subscription we can send a message to the Control Bus (see figure). We can even make the individual components smart enough to track all channels it has already used to avoid duplicate control messages. This approach seems to be a fair compromise between the other two approaches. We can track dynamic communication between components, such as usage of Return Addresses but avoid having to intercept every single message.
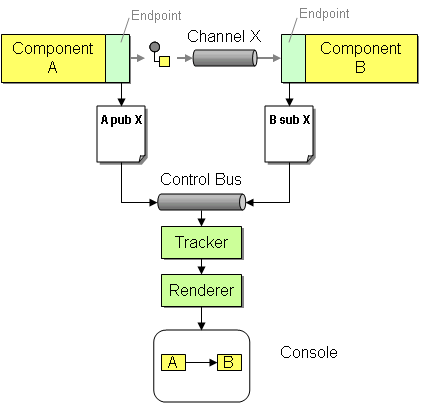
The second part of the bottom-up modeling approach is to visualize the data we captured. The dependency capture is likely to yield a list of components, each with a list of message channels that the component publishes or subscribes to. If Component A publishes to Channel X and Component B subscribes to the same Channel X we can essentially assume that Component A communicates with Component B. In a message flow diagram we would visualize this as an arrow pointing from Component A to Component B (see figure). Effective visual representation can be the key to understanding critical properties about a system that might otherwise go unnoticed (for some great example have a look at some of Ed Tufte's books). So far our approach has captured a directed graph as a data structure of nodes (components) and edges (communication dependencies). Transforming this data structure into a visually appealing and useful diagram is not a trivial task. Luckily, ATT Research has created a great open tool for graph visualization, GraphViz. GraphViz can render a multitude of graphs and has tunable layout algorithms. The only downsides of GraphViz are that it is file-based and that the file format pre-dates XML. Luckily, WingraphViz implements a COM wrapper so that we can avoid generating DOT files to feed GraphViz. Conveniently, COM components are easily invoked from .NET programs.
This all sounds good in theory but let's put all the pieces together and try this on a real implementation. A natural test candidate is the Loan Broker example in Chapter 9 of my book. The scenario is implemented using three different technologies and messaging paradigms. For our purposes, we chose the MSMQ / C# version because it is asynchronous and it does not depend on any third party software (for those of us who succumbed to the dominating force from the Pacific Northwest). Furthermore, the simplicity of the MSMQ API makes it well suited for examples like this one. The following figure shows the base architecture of the Loan Broker:
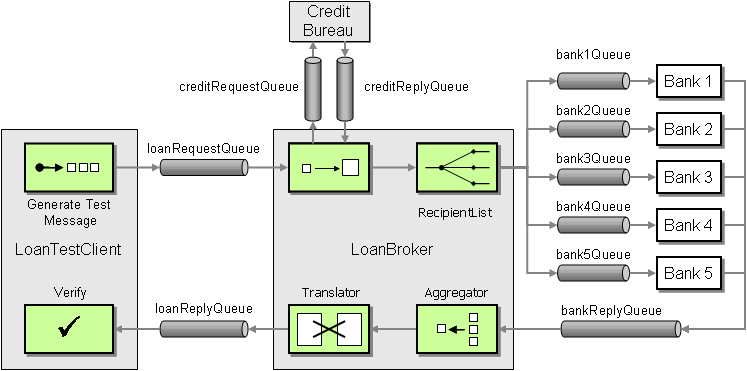
But let's realize that not everyone working with our system is going to have access to this pretty high-level picture or that the picture may be inaccurate because the solution changed over time. Therefore, we want to enhance the existing solution to support visualization of the message flow. First, we have to send a message to a control queue whenever a component accesses a message queue to receive or send messages. In order to minimize code changes to the existing loan broker solution, we need to make this tracing of publication or subscription as transparent as possible. Luckily, we had some apparent foresight when we developed the loan broker solution. We abstracted the components' interaction with the MSMQ MessageQueue objects behind the IMessageSender and IMessageReceiver interfaces. Defining these interfaces allows us to supplement different implementations for them without having to change the code for the messaging component. When we instantiate a component, the component constructor accepts references to these interfaces instead of actual MessageQueue objects. By passing references to the component, the outside components can control which implementation to use for each interfaces (see figure). This is very useful for testing or when you need to extend the default implementation (like we are doing now). We refer to this configuration as Dependency Injection .
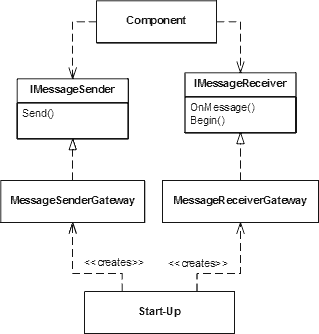
However, not all queues a component interacts with are known up front. For example, a service that supports a Return Address has to publish messages to queues that are not known at component start-up time. In order to accurately track dependencies between components we have to capture the fact that a component publishes messages to these queues. How can we intercept the instantiation of the MessageSenderGateway object by the component? Rather than letting the component instantiate the object directly using new we pass a factory to the messaging component. The messaging component uses the factory object to obtain references to the IMessageSender interface to send reply messages. Because the factory is invoked for each message queue reference it is the ideal spot to trace queue publication for visualization purposes.
For example the factory method to access a queue to send messages is implemented as follows:
public MessageSenderGateway GetSenderInstance(String q){
SendPublishTrace(q);
return new MessageSenderGateway(q);
}
protected void SendPublishTrace(string QueueName)
{
if (!SendQueues.Contains(QueueName))
{
PubSubTrace trace = new PubSubTrace(ComponentName, QueueName, QueueInteractionEnum.QUEUE_PUBLISH);
controlBusQueue.Send(trace);
SendQueues.Add(QueueName, null);
}
}
We notice one optimization in this code. Because a request-reply service component has to gain access to a queue for every reply message the default approach would send a publication message to the visualizer for every message. In reality, though, the reply queue is going to be the same for many messages. Therefore we make the factory smart enough to keep a list of queue names that have already been sent to the visualizer. This way we avoid sending duplicate messages onto the control bus.
Now that we can send a message to the control bus whenever a component publishes or subscribes to a message queue we have to write a console that reads the messages off the control bus and generates the dependency graph. The component then calls GraphViz to layout and render the corresponding graph as a GIF image. To see how the graph builds up over time I created a simple HTML page with a meta refresh tag to automatically reload the picture every few seconds.
So what does the visualization look like? It takes a few seconds for the complete graph to be generated because many dependencies are established by messages send to dynamic Return Addresses. The following picture shows the image produced by GraphViz:
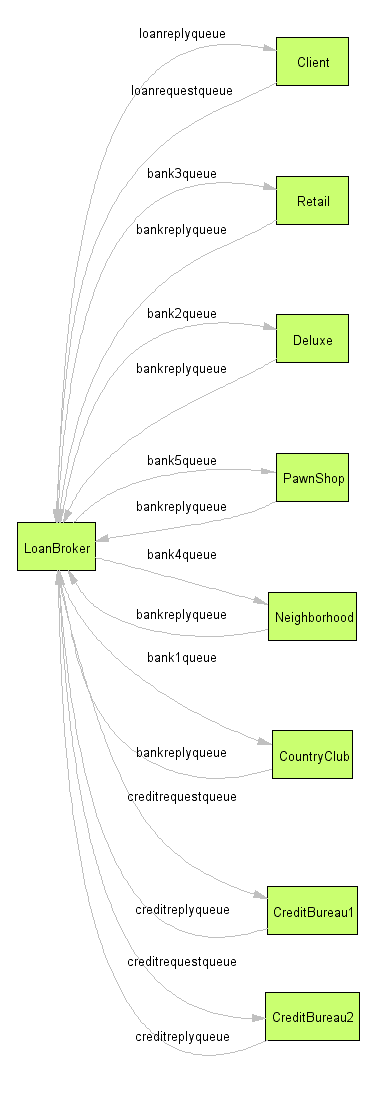
While the picture is not quite as pretty as our design diagram with the patterns icons, this generated image gives us some immediate information: The system we created uses one central component (the loan broker) to interact will all other components in a request-reply fashion. We can also see that the test configuration used two instances of the Credit Bureau component. Looking at the image it is immediately obvious which component faces the highest message traffic and could present a potential bottleneck. Visualization the message exchanges can help us identify the architectural style of our solution, in this case a central Process Manager with request-reply interaction (represented as circles in the graph) with all other components.
Generating diagrams from a running system can give us quick information about the type of system we created without having to model the complete system up front. I could imagine different types of diagrams for different purposes. For example if we are interested only in dependencies and not the complete message flow we might only track request messages and not reply messages in a request-reply interaction because the service provider does not actually depend on the service consumer. Or, rather than drawing lines directly between components we could depict the channel itself as a node. This way it would be easier to see that all Bank components in the Loan Broker example publish their replies to the same channel.
Taking things one step further, it would be interesting to investigate whether the resulting graphs can tell us more about the nature and quality of the solution. For example, we could count how many circles the graph has and what the average size of a circle is. Small circles imply more request-reply interaction, which could mean poorer scalability of the solution. It would be interesting to see whether we could identify certain patterns (or anti-patterns) from the graph data. This would be neat because the patterns now really look like (visual) patterns. What I created so far is a very simple but it could ultimately take on the shape of something like SALSA. One could even imagine some sort of query language against the graph to efficiently extract information from larger graphs. We could also augment the current system with message traffic data and depict the amount of message traffic by using different line weights in the graph.
Visualizing the dependencies between loosely coupled systems can be very useful and can be implemented with moderate effort. This way, the system can evolve organically without us having to pre-impose a predefined structure. At any point in time we can visualize what shape the system has taken on. This type of bottom-up visualization can be a viable and more agile alternative to top-down modeling


 Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.
Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.