
Let's Have a Conversation
Communicating inside a single program is simple: one method calls another, the result returns, and the calling method continues. Should anything go wrong during the call, an exception is thrown. If the program aborts altogether, both caller and callee share the same fate, making the interaction an all-or-nothing affair. This kind of binary outcome is a welcome behavior in the predictive world of computer software.
Communicating across systems is a bit more involved. The network introduces latency and unreliability while distributed systems have to cope with state being out of sync and the ability to make independent updates. As a result, procedure call semantics have proven to not be a good choice for distributed systems. Instead, these systems benefit from loose coupling and message-based communication, which simplifies the interaction model and, if used with message queues, provides temporal decoupling while increasing robustness.
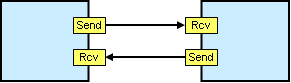
A message-based model splits the request–response interaction into two separate messages, one for the request and another one for the response. The consumer of a service initiates the request message and waits for the response while the service provider waits for request messages to which it replies with response messages. This setup means that the caller doesn’t have to sit around waiting for the response message. However, it requires the caller to associate incoming response messages with request messages it sent beforehand. This is usually accomplished with a Correlation Identifier that is shared across messages.
Do it Again
When implementing such an asynchronous request-response solution, a nagging question tends to arise: what should the caller do if the response message never comes? To be precise, this question consists of two separate considerations: first, what does never mean? Because computers don’t inherently understand the notion of infinite, “never” is generally represented as a time period that the user or application considers long enough, a so-called time-out. Second, what if "never" arrives and the sender still hasn’t received a message? This could happen for various reasons — a glitch in the communication could cause the request or reply message to be lost, or the server could consume the request message and then crash unexpectedly without sending a reply. In any case, the sender has essentially two choices: give up or resend the original request message.
It can be amusing how popular the try-it-again approach is in the generally very predictive field of computer science. If something doesn’t work, even the most rational computer scientist is inclined to just try it again. Even more shockingly, things often do work the second time around!
So let’s assume the requestor decides to resend the request message. Several new considerations come into play: if the time-out resulted from a lost response message, the service provider now receives the same request message a second time. Yet, in many cases, the provider shouldn’t perform the requested action a second time, meaning it must be an Idempotent Receiver. To act in an idempotent manner, the receiver must be able to distinguish a resent, and therefore duplicate, message from a distinct request that happens to contain the same data. A unique correlation identifier, a magic number included in the message, can help: a resent request would have the same correlation identifier and could be identified it as a duplicate by the receiver. The provider would then skip the repeated service request and simply return the previous response message. Resending messages thus requires both service consumer and provider to keep some state: the consumer needs to keep the request message to be able to resend it, and an idempotent provider must keep a list of received message IDs together with the original responses.
The service consumer has to deal with duplicate messages as well. For example, the provider might have sent a response through a message queue just as the consumer gave up waiting. In that case, the consumer resends the request message and receives the original response a fraction of a second later. However, a second response message, based on the resent request, will arrive a little later. Given that the consumer has already processed the first response, this message should probably be ignored, requiring the service consumer to be idempotent as well.
So much for duplicate messages, but what happens if the consumer still receives no response after resending the request message? It might be tempted to resend the message once more, but what if the response never arrived because this particular request crashes the server? Repeatedly resending such a “poison message” will just continue to crash the service provider. Therefore, the consumer should limit the number of retries and eventually give up.
Conversations
Suddenly, the interaction between service consumer and service provider looks much more involved. Both parties have to track the interaction state, have time-out mechanisms, count the number of retries, and eliminate duplicate messages. Instead of simply invoking a method, the two systems are engaged in a conversation, an exchange of related messages over time.
Because multiple conversations tend to occur at the same time (in real life as well as in distributed systems), messages are associated with the correct conversation through a correlation identifier (such as an order number) or context (the sender’s name or subject line in an email, for example). When receiving a message, a participant can use these identifiers to recover the appropriate conversation’s state and execute the next step in the conversation, which often includes sending a follow-on message.
Robust conversations have to deal with a number of challenges: lost messages, duplicate messages, participants failing and losing state, error conditions, concurrent actions, etc. Systems also need to find each other in the first place before starting a conversation. How do participants know when the conversation is over? What if one conversation partner disappears in the middle of the conversation? Accounting for all these scenarios when designing a conversation is no simple task. This book therefore presents a pattern language that helps architects and developers with the design of conversations.
Conversation between services have many analogies in real life. Humans frequently converse through asynchronous message exchange, such as when leaving a voice mail, mailing a letter, or sending an email. You might call a store to ask for the availability of a certain product. The store clerk might be busy and promises to call you back. If you haven't heard from him by late afternoon, you decide to give him another call. In another context, an assistant who is asked to arrange a meeting time contacts each meeting participant to check for available times. After the participants respond with their respective availability, the assistant will determine time slots that suit everybody. If there is no such time, he or she may try to negotiate with some participants. Ultimately, the coordinator will inform all participants of the agreed meeting time. Shortly before the meeting the coordinator might send a reminder notice to all participants (see figure).
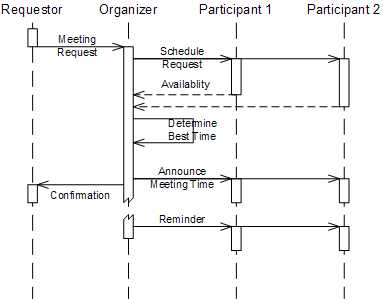
Scheduling a meeting as a simple conversation example
A conversation is defined via the following considerations:
- Participant Roles - you need to define who is involved in the conversation, for example the meeting requestor, the coordinator, and meeting participants.
- Message Types - participants need to understand different kinds of messages and how they impact the conversation. For example, meeting participants must respond to a Schedule Request message with an Availability message.
- Protocol - once participants and message types are defined, one can define which message exchanges between which participants are "legal". For example, is the coordinator allowed to send repeated Schedule Request message? Are confirmations required or optional?
The figure above uses a UML sequence diagram to depict the "meeting planning" conversation. This notation doesn't express all rules of the conversation protocol, though. It can only describe one possible flow of messages. For example, it cannot express whether the conversation is limited to two participants, whether participants are required to respond to requests in a specific order, or what happens in case a participant doesn't respond. The next chapter discusses how to describe conversations more precisely.
Conversation State
Conversations are stateful: a conversation sets the rules of allowed actions based on which messages have already been exchanged, i.e. the current state of the conversation. The simple Asynchronous Request-Response conversation from above has only a single state, "awaiting response", and the end state, "reply received". If no response message is received, the conversation remains in the "awaiting response" state indefinitely.
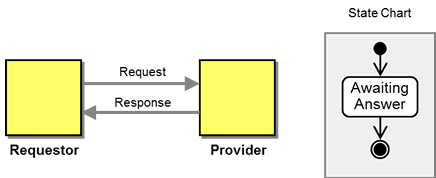
A very simple conversation with a single state.
If the rules of the conversation allow for retry (Request-Response with Retry), the state diagram becomes more complex as it has to assume a counter (a form of state) that tracks how many times a retry has been sent. After the maximum number of retries, the conversations ends in the "fail" end state. Instead of assuming a counter, you could also draw each retry as a distinct state as long as the allowed number of retries is small.
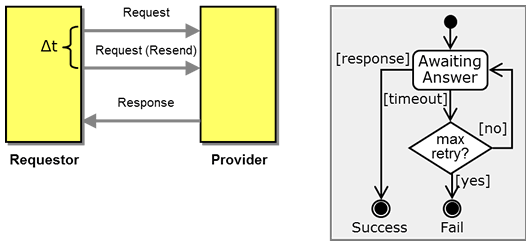
A very simple conversation with a single state.
So far we considered the conversation state to be in one overall "global" state. However, each participant also has a view on teh conversation state (see figure):
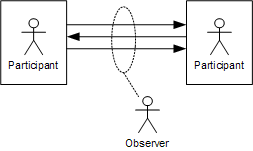
A conversation, seen from the perspective of an observer
- The participants initiate and respond to incoming messages. If there are more than two participants, each participant may only see part of the conversation. For example, when planning a meeting, each participant doesn't see the messages exchanged between the requestor and the organizer or between the organizer and the other meeting participants.
- An observer can see all messages in the conversation. However, he only listens on messages exchanged between the participants but does not send any messages. The modeling the conversation state from observer's point-of-view is called choreography, for example implemented by the Web Services Choreography Description Language [WS-CDL]. Most choreography implementations didn't find significant commercial success, partly due to the fact that they are not executable.
The participant state can differ from the global conversation state. For example, in Request-Response with Retry the provider doesn't have to track any conversation state - it simply responds to incoming messages (it may, however, be able to detect duplicate messages in order to be idempotent). Typically, participants implement the conversation by with a stateful process that sends and receives messages according to its role in the conversation (see figure). In the simple Asynchronous Request-Response conversation, the requestor will sends a request and then waits for a response. The provider does the opposite: it waits for incoming requests and sends corresponding replies.
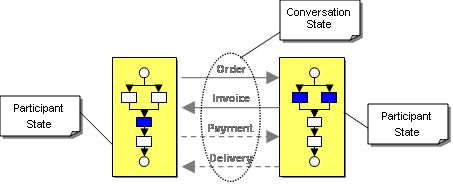
Conversation state and participant state
Each participant typically implements a more complex internal process to fulfill the purpose of the conversation. For example the provider in a Asynchronous Request-Response conversation might have to retrieve data from many sources and process it in order to form a response. The details of that process are not relevant for the conversation, though: we separate the interface process, which determines the conversation protocol, from the implementation process. The internal process of a participant is often expressed in form of orchestrations. These orchestrations are the domain of Web services standards such as the Business Process Execution Language [BPEL] or notations such as the Business process Modeling Notation (BPMN).
When designing conversations, it's possible to shift some of the responsibility between the participants. For example, a "smart" provider may be able to detect duplicate messages and therefore simplifies the design of the consumer.
Looking between the boxes
Of boxes and lines
Both messaging patterns ([EIP]) and Conversation Patterns look "between" communicating systems or applications. They examine how systems interact and how tightly they are coupled. When considering the behavior of a connected system, the way components interact has often a bigger impact on the overall system behavior than the parts themselves. It's a bit like cooking: good ingredients are a promising starting point, but they can easily be ruined but also turned into a fabulous meal. Too many times architects look at the boxes rather than between them, possibly because they are easier to grasp. Messaging and Conversation Patterns aim to give architects and developers an expressive but intuitive vocabulary to help them reason about what's between the boxes.
Coupling
One of the key properties that arise between teh boxes is the notion of Coupling. Coupling is a major consideration in distributed systems design, best defined as a measure of the dependencies between systems: the more assumptions two systems make about each other, the more tightly coupled they are. The fewer assumptions they make, the more loosely coupled they become.
| Loose coupling enables independent variability of connected systems. |
Loose coupling enables independent variability among the participants, allowing for example one component to change its implementation technology or its version without affecting other systems. In an enterprise-wide or inter-enterprise (i.e., B2B) integration scenario, independent variability has considerable value because one party usually doesn't have control over all applications, meaning that some components can change without central coordination or approval. For example, if a business partner decides to upgrade to the latest version of SAP there is little one can do to stop them. In the reverse scenario, your business might need to update components without being able to force the other side to make the corresponding change.
Loose coupling brings benefits, but as with most architectural decisions, there is no free lunch - it's all a matter of trade-offs. David Orchard aptly concluded that the only way to make two systems truly loosely coupled is by not connecting them at all. Unsurprisingly, this solution is not particularly useful. How much coupling and therefore how much dependency to introduce or not to introduce becomes an interesting question.
| “How do you make two systems loosely coupled? Don't connect them.” -- David Orchard |
Coupling isn't a binary property. Instead, it's a continuous range over multiple facets. For example, if one application uses a technology-specific protocol such as Java RMI or .NET Remoting, it depends on the fact that the other end uses the same technology. If one endpoint changes the implementation technology, the solution breaks. This integration is therefore more tightly coupled than a solution that uses XML over HTTP or a technology-independent middleware. Two components that communicate via XML messages in a synchronous fashion are temporally coupled: if a provider is slow or only intermittently available, the requestor also becomes slow or only intermittently available. Loose coupling, in this case temporal decoupling, can make systems more robust by limiting failure propagation.
The following list summarizes the main facets of coupling between communicating systems:
- Technology Dependency occurs when communicating systems are bound to common technology. Many remote communication mechanisms, for example JMS, Java RMI, JINI, or .NET Remoting, impose this dependency to allow a convenient programming model that can not only exchange data but also live objects containing both code and data. If one endpoint was going to be migrated from Java to .NET, this type of integration would break, underlinign the coupling introduced by the technology dependency. Technology dependencies can also be introduced by lower layers in the technology stack, such as the operating system or the processor architecture. For example, Intel-processor based PCs use a "little endian" encoding where the least significant portion of a multi-byte value (e.g., a 32 bit word) is stored in the first memory address. In contrast, many workstation processors, used a "big endian" system, which stores the bytes in the reverse order. If systems with a different endian notation exchange numeric values in byte order, the receiving system will vastly misinterpret the numeric data. Requiring the same processor architecture constitutes a strong form of technology dependency.
- Location Dependency - For one system to communicate with another it has to specify the destination of the communication. One can imagine various degrees of coupling in the specification of a location. A local method call is one of the most tightly coupled location dependencies: the target has to reside in the same virtual machine as the sender. In distributed systems, a destination can be provided as an IP address or a static URL. Looking up the destination URL in a directory reduces coupling because the address can change. Sending data to a logical Message Channel or in a shared blackboard further reduces location coupling. Location independence is a key enabler of composability: if one component does not make location assumptions about the components it is interacting with, it can be combined with different components without coding changes.
- Data Format Dependency depends on how data elements exchanged between systems are represented (see also [EIP, p.87]). Even if systems avoid encoding data in a processor dependent format ("little endian" vs. "big endian"), the size data items may differ: an integer number may consist of 32 bits on one system and 64 bits on another. Character strings might consist of 8 bit ASCII characters, EBCDIC values, or UNICODE characters. Therefore, both systems have to agree on a common data representation scheme. Some encodings, like fixed format EDI records, rely on a particular order of parameters, which breaks when adding or removing data items. "Tagged" formats such as name-value pairs, XML, or JSON documents loosen up such constraints and reduce coupling.
- Temporal Dependency is subtle and often overlooked. If systems communicate synchronously, i.e. the sender waits for the response, the requestor is temporally dependent on the provider: a slow provider causes the requestor to also be slow. If the providing system is unavailable, the requesting system is also rendered unavailable. In distributed systems where network latency, which may be outside of the applications' control, adds to the response time. Asynchronous messaging solutions cannot magically make an unavailable system available but they can temporally decouple systems.
- Programming Model Dependency exists when systems share constructs like classes, object instances, references, inheritance, polymorphism etc. Simple interaction models, such as document passing across asynchronous channels abstract from the underlying programming model and therefore provide a lower degree of coupling between the systems.
The following table summarizes the facets of coupling along with prototypical loosely and tightly coupled examples.
| Dependency | Loosely Coupled Example | Tightly Coupled Example |
| Technology | ReST, XML over HTTP | Java RMI, .NET |
| Location | Registry Lookup | IP Address |
| Data Format | XML, Comma-Separated Values | Binary, native encoding |
| Temporal | Asynchronous | Synchronous |
| Programming Model | Document-Oriented | Object-Oriented |
To Couple or Not to Couple
How much coupling is right? As with most architectures, there is no simple answer -- architecture is always a matter of trade-offs. Tightly coupled systems can get a bad rap because loosely coupled systems promise a whole range of architectural benefits. However, equating loosely coupled with "good" and tightly coupled with "bad" can lead to a what Martin Fowler calls "the Architect's Dream, the Developer's Nightmare": a system that is very flexible, but very difficult to work with.
Looking at some of the pros and cons of loose and tight coupling helps find the right balance. Supporting variability that is unlikely to occur can make the system more complicated and typically less efficient without realizing tangible benefits. Providing variability for future changes is admittedly a guessing game: you are building variability into the system because you don't know what changes the system has to undergo in the future. Hence, loose coupling is a bit like buying insurance; it's best when you don't need it, even though then you might feel like you wasted the money (or effort). But it's important to remember that you can't judge decisions by their outcome: you invested the extra effort to limit exposure to a known risk. The fact that the worst case scenario did not in fact occur afterwards does not influence the validity of that decision.
| Loose coupling is like buying insurance. It's best when you don't need it, but that doesn't mean you wasted your money. |
The best approach to identifying a suitable amount of variability is to clearly lay out variability events that could occur and rank them by probability (how likely it is that the event will occur), severity (the penalty incurred if the system doesn't support the change) and the effort required to build this kind of variability into the system. Such a table could look like this:
| Variability | Likelihood | Severity | Effort |
| Change in programming language | High | High | Low (can use XML/JSON) |
| An internal function is outsourced | Medium | Depends | Medium (can use XML, but need additional security) |
| Packaged application upgrades to next release | Almost certain | High for major packages | Medium (assuming backwards compatibility) |
| Change packaged application vendor | Medium | High for major packages | High - very difficult to absorb structural or semantic changes |
| ... | ... | ... | ... |
Some variabilities are easy to anticipate: if you have to connect systems that use different programming platforms and languages, your middleware has to be able to support communication across platforms. How likely is it that you need to replace the implementation of the CRM system with another vendor's product? Less likely, but the impact could be major if the data structures and models of the application change.
The following list includes some common coupling trade-offs:
Design-time Validation
In tightly coupled systems, the compiler can usually warn you of the most obvious mismatches between two communicating systems or methods, such as missing arguments, wrong data types, misspelled variable or method names etc. The compiler can do so because the rules for compatibility between caller and callee are well-defined and strictly enforced. This strictness is what makes the coupling tight -- it doesn't allow for variability. Loosening this coupling also reduces the ability to automatically validate the system at design time. For example, is the fact that an element is missing from a document an anticipated variability or a coding error?
Documentation
How do you express how much variability you are intending to support? Do you want to enforce the order of elements in a document or not? Should the system be resilient against the addition of elements? How about changing element data types? Common data schema definitions can express simple constraints such as the order of elements but cannot express more subtle differences such as a document that is too coarse grained or too fine grained.
Testing
A loosely coupled system can be more difficult to test because its support of independent variability increases the number of test cases. If a system doesn't depend on a specific order of the data elements, do you need to verify all possible permutations of parameters? Automated test cases bring some relief and also serve an important document function. Test cases such as testChangedElementOrder or testAdditionalElements will let anyone know what the intended resilience against change is, and it verifies it every time a change is made to the system.
Understandability
Loosely coupled systems are more difficult to understand. For example, in a tightly coupled, non-distributed system a developer can easily inspect the source code, see that one method calls another, and then navigate to that method. Most modern development environments include this option in the context menu or even provide a shortcut key. In a loosely coupled system, however, one method might post an event to a channel whose name is read from a configuration file. What other component, or components, receives this event? What activity or activities are performed as a result? Simple questions like this often require the developer to look at a number of source and configuration files or even to observe a running system. Without supporting tools this task can be extremely time consuming.
Current System State
Loosely coupled systems are designed to enable variability and evolution. The actual state of the system might therefore not be immediately apparent and manually maintained documentation is likely to be out-of-date. Therefore, in large, loosely coupled systems, automated visualization and documentation tools are essential. Creating such tools adds to the development cost and effort, though.
| Loosely coupled systems are designed to enable variability and evolution. Therefore, you can't presume the actual state of the system. |
Performance
Tightly coupled systems are generally more efficient than loosely coupled systems because the constraints imposed by the tight coupling allow optimization at build-time. For example, if system can rely that they will only communicate with systems equipped with the same run-time platform and processor architecture, they can stream bytes straight from memory onto the channel without any translation. To communicate with a wide range of parties the sending system needs to serialize, marshal and encode the data into a common format such as XML or JSON. The receiving system has to decode and parse the incoming data. Additionally, the systems might have to transmit metadata, such as the names or positions of data elements. This process consumes memory, CPU cycles and network bandwidth -- many XML documents are 10 to 20 times the size of comparable binary documents. Newer data encodings such as Protocol Buffers or AVRO place emphasis on data size and parsing overhead while retaining platform independence.
Undesired Variability
Sometimes you want things to break when they change. For example, if the sending system changes the time zone on a date field from PST (Pacific Standard Time) to GMT (Greenwich Mean Time), you would like to receive a warning rather than misinterpret incoming data. This requires a strict validation of data rules between sender and receiver as is typical in tightly coupled systems. In loosely coupled systems, these kind of problems often surface only at run-time when it may be too late.
False Decoupling
There's a risk to create systems that have "false decoupling", where you are led to believe that systems are loosely coupled but the property has never been verified. This condition can be actually worse than tight coupling because the system sets expectations that it then does not fulfill. It's like thinking you have insurance just to find out that your specific incident was not covered. Let's not build systems that require developers to read the "fine print"!
A common example of false decoupling is document parsing, which processes incoming XML documents, extracting relevant data values into objects. Problems occur if the interface contract specifies that the order of elements is irrelevant (thus allowing variability in the order of elements), but the parsing code steps through the list of elements, making implicit assumptions about the order of elements. As long as all systems use the same order of elements, the system will work fine. As soon as another system tries to take advantage of the advertised variability, the communication will break.
Coupling and Conversations
Loosely coupled systems minimize the assumptions they make about one another while still providing a meaningful interchange. This potential conflict provides the key forces for many of the Conversation Patterns in this book. More elaborate conversation protocols tend to introduce tighter coupling. For example, a conversation based on an object-oriented semantics introduces coupling due to the complexity, for example caused by the explicit allocation and release of object instances. However, a more sophisticated conversation can also reduce coupling. For example, if System A is trying to retrieve information from System B, the simplest conversation, a Asynchronous Request-Response, makes certain assumptions, for example guaranteed message delivery and a guaranteed response from System B. One can loosen up requirements on System B if you are willing to put more intelligence into System A. For example, System A can be enhanced to automatically retry an operation if it doesn't receive a response within a certain amount of time. System A can be further enhanced to ignore duplicate responses or to include a retry counter that instructs it to "give up" after a specified number of retries. System B will know rather little about these enhancements and has to make very few assumptions about System A. The overall interaction becomes more sophisticated without affecting System B (There is truly no impact on System B only if the interaction with System is idempotent, for example because it is a read operation.) .