
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Find my posts on IT strategy, enterprise architecture, and digital transformation at ArchitectElevator.com.
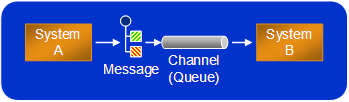
Messaging-based interaction introduces two new elements, a channel and a message. Despite their simplicity these new elements open up options and force new decisions. A deceivingly simple question is “how should the channel be named?” When one method called another directly there was no intermediate element and therefore no decision to make. Now that we afforded ourselves the new level of indirection we have to name it appropriately. Choices, choices...
In order to find an appropriate name for a channel we need to first determine what the channel should represent. Even though a channel can be a purely logical construct, it is the key mechanism that couples sender and receiver. Both sender and receiver of messages have to agree on a common channel name in order to exchange messages.
Let's look at a few obvious choices:
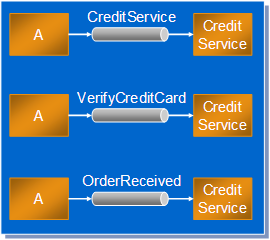 A very simple approach assigns each component its own channel. For example, a component
that deals with credit card validations could be called the
A very simple approach assigns each component its own channel. For example, a component
that deals with credit card validations could be called the CreditService and react to messages sent on a channel also named CreditService. If any component needs something related to credit it would send a message to that
channel. This simple approach does give us a level of indirection at the implementation
level -- we could replace one credit service implementation with another without anyone
noticing since the channel name would not change. The semantics of the interaction,
however, are not much decoupled. The caller still has to know which component provides
the functionality it requires, much like it does in a direct one-to-one interaction
between components.
VerifyCreditCard. It is important to keep in mind that these channel operations are not tied to a
specific class as is the case in object-oriented approaches. As a result, the caller
no longer has to know which component is able to service this type of request, increasing
the level of abstraction somewhat. Service-oriented computing generally follows this
approach with the only caveat that the operation is typically tied to a specific service
(interface).
OrderReceived. This simple change in name signifies a fairly significant shift in responsibility.
The message on the channel no longer represents an instruction but rather an event,
a notification that something happened. How a receiver responds to this event is completely
hidden to the sender. We also no longer assume that there is a single recipient for
the event -- the event might be processed by more than one subscriber. For example,
a new order not only has to go through credit checking but inventory might also have
to be verified. Again, the assumptions between the communicating parties have been
reduced. As a result, EDA is often considered to be more loosely coupled than SOA.
Communicating through events as opposed to commands indicates a subtle but important shift of responsibility. It allows components to be decoupled to the extent that the “caller” is no longer aware of what function is executed next nor which component is executing it. Another equally important shift of responsibility between caller and callee is that of keeping state.
![]() In a system that is based on queries and commands state is usually kept in one application
that is considered the “master” for the data. When another application needs to reference
that data it sends a query to the owning application and waits for the response before
it continues processing. For example, when an order management system needs to fulfill
an order it queries the customer management systems for the customer’s address so
it can instruct the shipping application to send the shipment to that address.
In a system that is based on queries and commands state is usually kept in one application
that is considered the “master” for the data. When another application needs to reference
that data it sends a query to the owning application and waits for the response before
it continues processing. For example, when an order management system needs to fulfill
an order it queries the customer management systems for the customer’s address so
it can instruct the shipping application to send the shipment to that address.
Event-driven systems work differently, almost to the inverse. Systems do not query other systems for information but instead keep their own copy of the required data and listen to updates as they occur. In our example this would mean that the shipping system keeps its own copy of the customer’s address so when an order arrives it can use that address to label the shipment without having to query the customer management system. While replicating data this way might seem dangerous it also has advantages. The customer management system simply broadcasts changes to the data without having to know who all keeps a copy. Because the customer management is never queried for address data it never becomes a bottleneck even as the system grows and the demands for address data multiply.
![]() The principle behind the shift in responsibility is once again tied to the concept
of coupling. In a loosely coupled interaction a source of data should not be required
to keep state at the convenience of its communication partners. By shifting the burden
of keeping state to the consumer the component is can be completely oblivious to the
needs of the data consumers – the key ingredient into loose coupling. The shift away
from the query-response pattern of interaction means that many components have to
act as event Aggregators: they listen to events from multiple sources, keep the relevant state and combine
information from multiple events into new events. For example, the shipping system
effectively combines address change events and order events into request for shipment
to a specific address.
The principle behind the shift in responsibility is once again tied to the concept
of coupling. In a loosely coupled interaction a source of data should not be required
to keep state at the convenience of its communication partners. By shifting the burden
of keeping state to the consumer the component is can be completely oblivious to the
needs of the data consumers – the key ingredient into loose coupling. The shift away
from the query-response pattern of interaction means that many components have to
act as event Aggregators: they listen to events from multiple sources, keep the relevant state and combine
information from multiple events into new events. For example, the shipping system
effectively combines address change events and order events into request for shipment
to a specific address.
It sounds like event-based systems surpass command-and-control systems across the architectural "score card". They are more loosely coupled and allow free composition of individual components into a larger system, thus aiding reuse and flexibility. Additionally, they can provide a natural mapping of a problem space into the system model. After all, many interactions in the real world are based on events. So are non-event-based systems for losers? Not quite -- as always, there is not free lunch, at least outside Google. Dynamic, loosely coupled systems are inherently difficult to design and debug (see Good Composers are Far and Few in Between). So we need to make sure to have the right tools at hand (for example, see Visualizing Dependencies) and to gain experience by making mistakes early in a small scale.


 Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.
Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.