
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Find my posts on IT strategy, enterprise architecture, and digital transformation at ArchitectElevator.com.
IT loves virtualizing stuff, following the old rule that in computer science every problem can be solved by just one more level of indirection. Cloud computing is based on virtualization of compute resources - you don't need to know which physical machine your application is actually running on and you can get new ones with the click of a button. Before cloud was a buzzword, though, VMware and others have virtualized machines at the operating system levels. Recently (in terms of buzz, not technology), containers bring another level of light-weight virtualization of computing resources. And let's not forget the Java Virtual Machine, which also claims a level of virtualization. What are we supposed to do with all these levels of virtualization?
Virtualization turns physical resources into logical resources, which are more flexible and often available on demand. Think of it as a rental car as opposed to owning a car: you can rent a convertible in nice weather, a four-wheel-drive in the winter and a wagon (estate) for hauling stuff. And you pay for them only when you need them. Buying all these cars would be highly inefficient, especially when you rarely use them (I actually own a wagon and a convertible, so I know). Making things virtual allows you to create new instances of something from existing resources - like renting a car from a large pool. In the software world we have some added flexibilities: we can instantiate different operating systems, such as Windows or Linux, on the same hardware and a hypervisor or can turn one large physical machine into multiple small virtual machines. This is where the rental car analogy runs out of steam: turning wagons into convertibles is a lot harder and one car can hardly be segmented into two motorcycles.
 OS-level virtualization has been around for a long time. A hypervisor manages and
abstracts machine hardware, so you can create new operating system instances of varying
flavors and sizes on a fixed set of physical hardware. This is old news in the mainframe
world and the likes of VMware have been offering this for quite some time on x86 platforms,
reducing machine deployment times and costs while increasing resource utilization.
OS-level virtualization has been around for a long time. A hypervisor manages and
abstracts machine hardware, so you can create new operating system instances of varying
flavors and sizes on a fixed set of physical hardware. This is old news in the mainframe
world and the likes of VMware have been offering this for quite some time on x86 platforms,
reducing machine deployment times and costs while increasing resource utilization.
Most internet giants don't use hypervisors internally, though, because they carry a certain overhead in the 5-15% range and cost a good bit of licensing money if you use a commercial product. If you have 100 machines this is likely not a big deal, but if you have 100,000 machines, you are going to want something different. Most public clouds do use hypervisors, e.g. KVM for Google Compute Engine or Xen for Amazon EC2, because they have to support multiple operating system vendors and versions.
Today's large computing infrastructures often use containers, typically based on Linux LXC technology: multiple containers run on a single operating system instance and thus carry less overhead than separate OS instances. They usually also provide less isolation between instances -- something to consider if your business requires PCI compliance or the like. Big infrastructures typically use cluster management software like Mesos or Kubernetes to allocate workload across a large number of containers. We did this at Google many years ago at grand scale.
The Java virtual Machine was also popularized as the virtualization layer of choice - "write once - run anywhere". In addition to byte code abstraction, J2EE containers also provided run-time abstraction by managing multiple applications running on a single server by means of thread pools and the like. Multiple Java applications can be hot-deployed to such (Java) containers through WAR files.
Many of today's modern software stacks also provide a level of virtualization by operating independently from the number and identity of the compute nodes underneath. MapReduce and its cousins are built on this principle: they manage workload distribution, process restarts and all the other nasty stuff inside their framework. On one hand, this allows the application to not have to worry about it and and on the other hand it reduces the need for infrastructure management features.
Virtualization has a clear user benefit: computing resources become available on demand without setting up and wiring new physical hardware. Better yet, the virtualization layer makes this (largely) transparent to the application layer by abstracting implementation details. The ability to divide physical resources into many logical units also improves utilization and therefore cost efficiency: you can buy larger servers and use them in small increments without changing the way the software is written.
Vendors love to provide a virtualization layer for another reason: it positions them right in the middle of the computing ecosystem, holding a central role that is difficult to replace. For example, VMware ESX is widely used and central to many IT infrastructures. While the hardware virtualization is largely transparent to the application, provisioning and management tools are not and result in a certain amount of vendor lock-in. OpenStack will bring some relief in this area, but implementation maturity still varies.
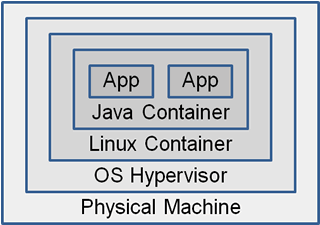 How many virtualization layers does one need, though? Running a Java App in a Java
Container in a Linux container on top of a virtual machine starts to look like a Matryoshka Doll: little dolls stacked one inside the other. I call this Virtualization Matryoshka: many layers of virtualization stacked inside each other. While matryoshka dolls
are entertaining, you probably have a feeling that this is not the most efficient
setup for a run-time infrastructure.
How many virtualization layers does one need, though? Running a Java App in a Java
Container in a Linux container on top of a virtual machine starts to look like a Matryoshka Doll: little dolls stacked one inside the other. I call this Virtualization Matryoshka: many layers of virtualization stacked inside each other. While matryoshka dolls
are entertaining, you probably have a feeling that this is not the most efficient
setup for a run-time infrastructure.
Too many layers not only bring complexity and overhead, but also don't add much benefit. The natural question then is what layer(s) we should eliminate. For Java applications, we probably do want to keep the JVM, but there is a clear trend towards lighter-weight, embedded containers whose job is not to run many applications, but a single application with as little abstraction as possible. This does away with one virtualization layer at the application server level.
PaaS (Platform-as-a-service) platforms, which tend to leverage containers, are starting to eliminate the operating system VM layer by deploying on physical machines in a so-called "bare metal PaaS" approach. You will need a component that manages these physical machines, but much of that can be hidden underneath the PaaS model, making it largely transparent to the application deployer. OpenStack is also looking at a bare-metal implementation of Nova, which runs under the name Ironic. All we need is an implementation for open compute and we are set to go.
Removing layers will provide an up-tick in performance and reduced license cost for the virtualization layer. This may be most pronounced in I/O heavy and low-latency or high-performance compute applications. I believe eliminating a few layers of virtualization is a healthy trend. Layering is fine - Matryoshka Dolls are amusing but not efficient.


 Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.
Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.