
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Find my posts on IT strategy, enterprise architecture, and digital transformation at ArchitectElevator.com.
One of my favorite pastimes is to argue with people whether a solution is stateless, whether it should be stateless and what it means to be stateless in the first place. Ideally, the debate would involve alcoholic beverages and the other person would pick up the check. After "loosely coupled", "stateless" must be a close runner-up as the ultimate nirvana in buzzword-compliant architectures. It is also equally hotly debated. Today, I 'd like to share my view on state and lessness. If you disagree you are welcome to argue with me, but you are buying! :-)
State is like the Matrix. It is everywhere around us but most of the time you don't notice it. Every modern computer is stateful. A Turing machine is stateful, in particular the band holds state and the head is at a certain position, which is also state. Every modern computer has an instruction counter that points to the next instruction to be executed. That is state. Almost every modern machine has a call stack that remembers which methods you executed last. That is state, too. I think the last truly "stateless" computer I can think of are analog computers, wired together from transistors and resistors. But even those have a stateful element, the capacitor. So, chances you are whatever you build outside of an op-amp, it is stateful. Get over it.
Once we get this part out of our system, the debate of statelessness becomes a lot more productive. So the question is not whether a system has state, but rather:
So I hope we all agree that every modern computer system is stateful. So how can we talk about stateless systems? The key is whether the statefulness matters at our level of abstraction. If I look at a system from the perspective of service consumers communicating with service providers state such as the instruction pointer does not matter. It is not relevant to the discussion at the chosen level of abstraction. If I talk about designing the thread management part of the operating system in the very same environment, then the instruction pointer is a very important piece of state that needs to be stored and restored during a task switch. So any debate of statelessness is futile unless a clear level of abstraction is set and agreed upon first.
One reason state might be irrelevant is because it is below the agreed upon level of abstraction. Another reason state might be irrelevant is because it is easily recoverable. Loading a static routing table into a messaging component would fall into such a category. If the table is completely static or quasi-static, a component can easily load or re-load that table from disk or a database. Holding the table in memory technically speaking makes the component stateful, but it does not really matter as the state is not impacted by the messages traveling through the component and can be recovered at will. If the component shuts down and restarts this extra state has no impact. Likewise, if a bank of processing nodes processes incoming messages it does not matter which node processes a message because they all loaded the same configuration and the configuration is not impacted by past messages consumed by a particular component.
One type of state that is likely to be relevant to a messaging system is the conversational state. A Conversation is a sequence of coordinated message exchanges. The conversational state defines where in that sequence of message exchanges a conversation is. For example, a conversational state could be that component A has made a request and is now waiting for the reply. Or, that component A has subscribed to events from component B with the subscription due to expire in 10 minutes.
This state information is quite relevant and typically has to be shared between the participants. There are also a number of different places where this state can be kept and a discussion of where that should be is in fact quite relevant to designing a successful integration or messaging solution. So where could part of this conversational state be kept?
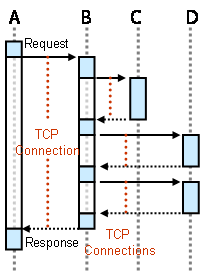
TCP Stack
One equally popular and inefficient way to represent the state of the conversation is the TCP stack. How so, you might ask. This happens when the architecture (ab)uses HTTP-based Web services calls as RPC's: one component invokes a service, holding an open HTTP (read TCP) connection. In a service-oriented environment it is likely that the service in turn accesses another service. As a result, yet another TCP connection is established and held for the duration of this request-reply interaction. Essentially, we built some form of distributed call stack via a set of open TCP connections (see figure). The TCP stack is chartered with correlating incoming response data packets to the right process waiting for a response. The advantage is that the application process does not have to worry about correlation. The downside is that we use the TCP stack as a surrogate call stack for a distributed system with long-running interactions. This can quickly lead to a huge number of open connections, something a TCP stack is usually not designed to handle. Also, we can easily imagine that a dropped connection can quickly bring the house of cards down because the connections make up the conversation state.
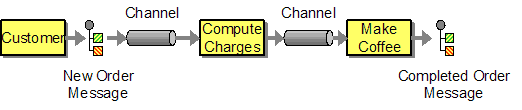
Message Queues
In order to remove the dependency on the TCP stack for state management we can use asynchronous message channels to communicate between parties. Message passing is asynchronous, so there is no need to keep state in the network connection itself. If the messages contain all information necessary for a component to complete a processing step, the resulting architecture is a true Pipes-and-Filters architecture because no state is shared between the components ("filters") outside of message passing. This approach makes for a highly scaleable message flow architecture, however, real life constraints often often force a compromise on this pure architectural style. For example, complex conversations almost always require some state to be kept in the endpoints or an explicit conversation coordinator. Also, this approach often makes it inefficient to monitor the state of a conversation. Because the state of the conversation is represented by a message sitting in a specific message queue, each message queue might have to be inspected.
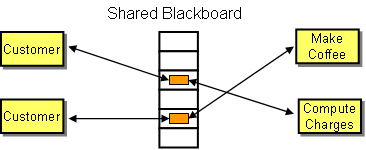
Shared Blackboard
A more generic version of a message queue is a shared blackboard or scratchpad. This blackboard acts as a shared memory space to allow distributed components to communicate with each other. They do so by placing entries in form of tuples into the blackboard. The blackboard does not impose an order for entries in the way that a message queue does for messages (i.e. FIFO). Recipients simply look for tuples that match their specified criteria (typically the type of the object plus and specified public property fields). The blackboard will return a reference to any entry that matches the request. This architecture is most prominently implemented in JavaSpaces. The advantage is that the state of the conversation can be more easily obtained by inspecting the blackboard. The downside is that a shared blackboard can become a bottleneck in a large distributed system.
In the Endpoints
In order to track more complex conversations a portion of the conversation state is typically kept in the communication end points. In an asynchronous conversation, each conversation partner has to "remember" what to do next once a message comes in. This implies that the endpoint has to have some concept of how far the conversation is. For example, if a component sent a request message it typically knows that it is waiting for a reply message. Also, it might keep internal state data to be carried over to the processing of the reply message. When the reply message arrives, the component uses the Conversation Identifier to retrieve this state context.
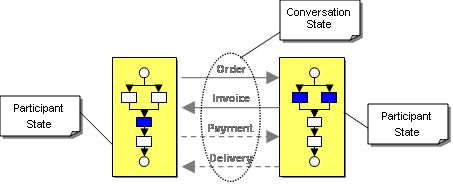
Conversation Coordinator
In more complicated multi-party conversations, a conversation coordinator might be added into the mix. The sole role of this coordinator is to track the conversation across the multiple parties. In a multi-party conversation each individual participant may only have a partial view of the conversation. A conversation coordinator may be required to make decisions that require knowledge of the whole conversation. This model is commonly used to implement 2-phase commit protocols using a transaction coordinator.
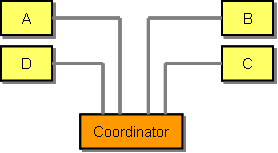
I hope that this brief overview illustrates the fact that there is often more to statefulness and statelessness than initially meets the eye. Distinguishing what kind of state is kept where and whether this state is relevant is an important first step to having a debate related to this topic.
Thanks to Michael Qvortrup for an enlightening discussion on this topic at OOPSLA. It motivated me to finally write this rambling up (with a 6 week delay...).


 Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.
Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.