|
Overview
This chapter demonstrates how to compose routing and transformation patterns into a larger solution. We chose to model the process of a consumer obtaining quotes for a loan from multiple banks. We simplified the process a little bit so we can focus on a discussion of integration patterns as opposed to holding a lecture in consumer financial services. Based on the patterns that we defined we discuss and create three alternative implementations for this process, using different programming languages, technologies and messaging models.
Obtaining a Loan Quote
When shopping for a loan, a customer usually calls several banks to find the deal with the best possible interest rate. Each bank asks the customer for his or her social security number, the amount of the loan and the desired term , i.e. the number of months until the loan has to be paid off. Each bank then investigates the customer's credit background, usually by contacting a credit agency. Based on the requested terms and the customer's credit history, the bank responds with an interest rate quote to the consumer (or declines thankfully). Once the customer has received quotes from all banks, he or she can then select the best offer, i.e. the lowest interest rate.
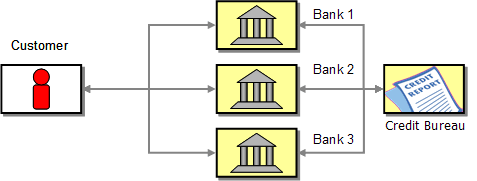
A Consumer Talking to Banks to Get a Loan Quote
Because contacting multiple banks with a loan quote request is a tedious task, loan brokers offer this service to consumers. A loan broker is typically not affiliated with any one bank but has access to many lending institutions. The broker gathers the customer data once and contacts the credit agency to obtain the customer's credit history. Based on the credit score and history, the broker presents the request to a number of banks that are best suited to meet the customer’s criteria. The broker gathers the resulting quotes from the banks and selects the best offer (i.e. the lowest interest rate) to pass back to the consumer.
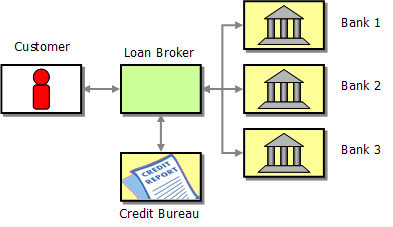
A Loan Broker Acting as Intermediary
Designing the Message Flow
We want to design a loan broker system using integration patterns in the previous chapters. To do this, let's first list the individual tasks that the loan broker needs to perform.
- Receive the consumer's loan quote request
- Obtain credit score and history from credit agency
- Determine the most appropriate banks to contact
- Send a request to each selected bank
- Collect responses from each selected bank
- Determine the best response
- Pass the result back to the consumer
Let's have a look to see which patterns could help us implement the loan broker. The first step describes how the broker receives the incoming request. We cover this topic in much more detail in the following chapter on endpoint patterns. So for now, let's skip over this step and assume the message is somehow received by the broker. Now, the broker has to retrieve some additional information, i.e. the customer's credit score. A Content Enricher sounds like the ideal choice for this task. Once the broker has the complete information, the broker has to determine the appropriate banks to route the request message to. We can accomplish this with another Content Enricher that computes the list of recipients for the request. Sending a request message to multiple recipients and re-combining the responses back into a single message is the specialty of the Scatter-Gather. The Scatter-Gather can use a Publish-Subscribe Channel or a Recipient List to send the request to the banks. Once the banks reply with their rate quotes, the Scatter-Gather aggregates the individual rate quotes into a single quote for the consumer using an Aggregator.
If we model the message flow using these patterns, we arrive at the following design:
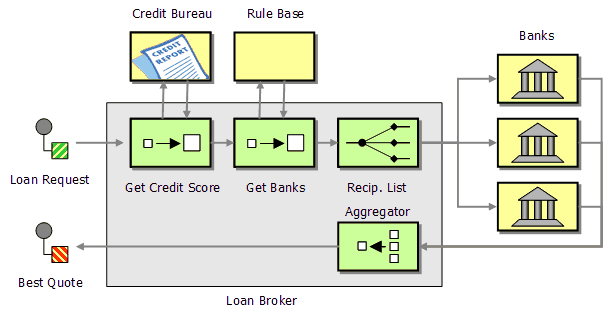
Simple Loan Broker Design
We have not yet accounted for the likely event that each bank may use a slightly different message format for the loan request and response. Because we want to separate the routing and aggregation logic from the banks' proprietary formats, we need to insert Message Translators into the communication lines between the broker and the banks. We can use a Normalizer to translate the individual responses into a common format:
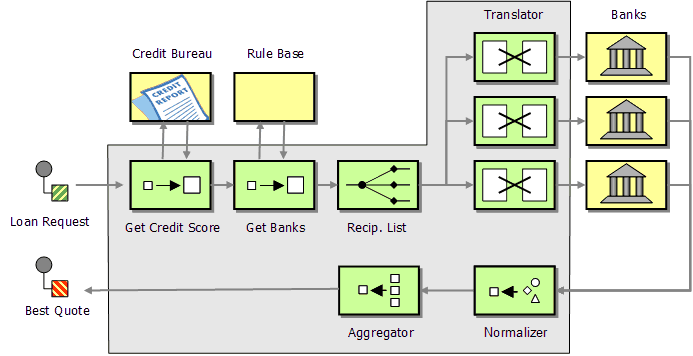
Complete Loan Broker Design
Sequencing: Synchronous vs. Asynchronous
So far, we have described the flow of the messages and the routing and transformation patterns we can use to describe the design of the loan broker component. We have not yet discussed the timing of the broker operation. We have two primary choices:
- Synchronous (Sequential): The broker asks one bank for the quote and waits for a response.
- Asynchronous (Parallel): The broker sends all quote requests at once and waits for the answers to come back.
We can use UML sequence diagrams to illustrate the two options. The synchronous option implies a sequential processing of all loan requests (see picture). This solution has the advantage of being simpler to manage because we do not have to deal with any concurrency issues or threads. However, it is an inefficient solution because we do not take advantage of the fact that each bank possesses independent processing power and could be executing requests simultaneously. As a result, the consumer might have to wait a long time for an answer.
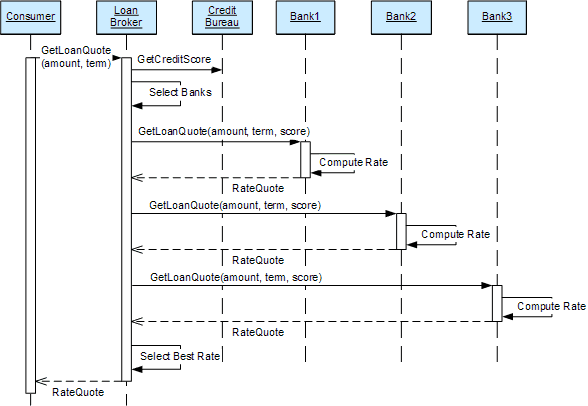
Synchronous, Sequential Processing of Loan Requests
The asynchronous solution issues all requests right away so that each bank can start processing. As the banks finish the computation, they return the results to the loan broker. This solution allows for a much quicker response. For example, if all banks take a similar amount of time to produce a loan quote, this solution is almost n times faster where n is the number of banks we are dealing with. The loan broker now needs to be able to accept the loan quote messages in any order because there is no guarantee that responses arrive in the same order that requests were made. The following sequence diagram illustrates this option. The half arrowhead on the loan quote requests indicate asynchronous invocations.
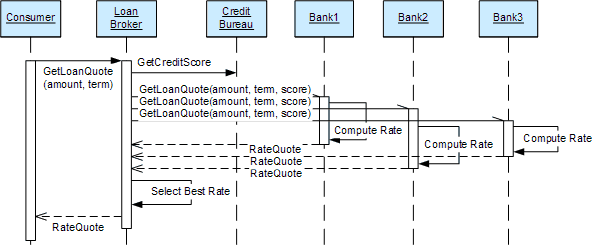
Asynchronous, Parallel Processing of Loan Requests
Another significant advantage of using asynchronous invocation over a message queue is the ability to create more than one instance of a service. For example, if it turns out that the credit bureau is a bottleneck, we could decide to run two instances of the credit bureau component. Because the loan broker sends the request message to a queue instead of directly to the credit bureau component it does not matter which component instance processes the message as long as the response is put back onto the response channel.
Addressing: Distribution vs. Auction
Using a Scatter-Gather to obtain the best quote allows us to choose from two addressing mechanisms, a Recipient List or a Publish-Subscribe Channel. The decision primarily depends on how much control do we want to exert over the banks who are allowed to participate in a specific loan request? Again, we have a number of choices:
- Fixed: The list of banks is hard-coded. Each loan request goes to the same set of banks.
- Distribution: The broker maintains criteria on which banks are a good match for a specific request. For example, it would not send a quote request for a customer with a poor credit history to a bank that specializes in premier customers.
- Auction: The broker broadcasts the request using a Publish-Subscribe Channel. Any bank that is interested is allowed to subscribe to the channel and 'bid' on the request. Banks can subscribe or unsubscribe at will. Each bank can still apply its own criteria on whether to submit a bid.
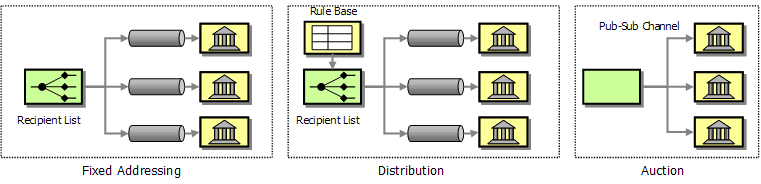
Which option is best for our scenario? As always, there is no simple "and the answer is...", but the choice is driven by both business and technical preferences and constraints. The first option is simple and gives the broker control over the list of banks. However, if new banks come and go frequently, the solution can result in an administrative burden. Also, the bank may not be happy to be receiving a bunch of irrelevant requests because each request incurs a certain internal cost for the bank. Also, to maintain the simplicity of this approach, the aggregation strategy is more likely to require banks to submit a response. Banks may want to reserve the right to withhold from the bid.
A distribution approach (using a Recipient List) gives the broker more control over which bank to involve in each loan request. This allows the broker to be more efficient by reducing the number of requests. It also allows the broker to prefer certain banks based on the business relationship. On the downside, it requires additional business logic to be implemented and maintained inside the loan broker component. Both the distribution and the fixed approach require a separate Message Channel for each participant in order to control the message flow.
Using a Publish-Subscribe Channel broadcasts a loan request to all subscribing banks and lets each bank determine which requests to service. Each bank can use a Message Filter or implement a Selective Consumer to filter out undesirable loan requests. This approach renders the loan broker pretty much maintenance free in case of adding or removing banks but it requires more work on the side of the banks. This solution requires only a single Message Channel, but it has to be implemented as a Publish-Subscribe Channel. Many efficient publish-subscribe schemes use IP Multicast that typically does not route across wide-area networks or the Internet. Other implementations emulate a Publish-Subscribe Channel by using an array of Point-to-Point Channels and a Recipient List. This approach preserves the simple semantics of a Publish-Subscribe Channel, but is less efficient in its use of channels and network bandwidth. For additional trade-offs between routing and pub-sub plus filtering, see the description of the Message Filter.
Aggregating Strategies: Multiple Channels vs. Single Channel
When receiving loan quotes from the bank we have similar design choices. We can have all banks submit their responses to a single response channel or we can have a separate response channel for each bank. Using a single channel reduces the maintenance burden of setting up a separate channel for each participating bank, but requires each bank reply message to include a field identifying the bank who issued the quote. If we use a single response channel, the Aggregator may not know how many response messages to expect unless the Recipient List passes this information to the Aggregator (we call this an Initialized Aggregator). If we use an auction-style Publish-Subscribe Channel the number of possible responses is unknown to the loan broker so that the Aggregator has to employ a completeness condition that does not depend on the total number of participants. For example, the Aggregator could simply wait until it has a minimum of three responses. But even that would be risky if temporarily only two banks participate. In that case, the Aggregator could time out and report that it received an insufficient number of responses.
Managing Concurrency
A service such as a loan broker should be able to deal with multiple clients wanting to use the service concurrently. For example, if we expose the loan broker function as a Web service or connect it to a public Web site we do not really have any control over the number of clients and we may receive hundreds or thousands of concurrent requests. We can enable the loan broker to process multiple concurrent requests using two different strategies:
- Execute multiple instances.
- A single even-driven instance
The first option maintains multiple parallel instances of the loan broker component. We can either start a new instance for each incoming request or maintain a 'pool' of active loan broker processes and assign incoming requests to the next available process (using a Message Dispatcher). If no process is available we would queue up the requests until a process becomes available. A process pool has the advantage that we can allocate system resources in a predictable way. For example, we can decide to execute a maximum of 20 loan broker instances. In contrast, if we started a new process for each request we could quickly choke the machine if a spike of concurrent requests arrives. Also, maintaining a pool of running processes allows us to 'reuse' an existing process for multiple requests, saving time for process instantiation and initialization.
Because much of the 'processing' required by the loan broker is to wait for replies from external parties (the credit bureau and the banks) running many parallel processes may not be a good use of system resources. Instead, we can run a single process instance that reacts to incoming message events as they arrive. Processing an individual message (e.g. a bank quote) is a relatively simple task so that a single process may be able to service many concurrent requests. This approach uses system resources more efficiently and simplifies management of the solution due to the fact that we only have to monitor a single process instance. The potential downside is the limited scalability because we are tied to one process. Many high-volume applications use a combination of the two techniques, executing multiple parallel processes each of which can handle multiple requests concurrently.
Executing multiple concurrent requests requires us to associate each message in the system to the correct process instance. For example, it may be most convenient for a bank to send all reply messages to a fixed channel. This means that the reply channel can contain messages related to different customers' concurrent quote requests. Therefore, we need to equip each message with a Correlation Identifier to identify which customer request the bank is responding to.
Three Implementations
In order to implement the loan broker example, we have three main design decisions to make: we have to select a sequencing scheme for the requests , we have to select and addressing scheme for the banks and we have to define an aggregation strategy. In addition we have to select a programming language and a messaging infrastructure. In aggregate, these individual options result in a large number of potential implementation choices. We chose to implement three representative solutions to highlight the main trade-offs between the different implementation options. As with all examples in this book, the choice of specific technologies is somewhat arbitrary and does not indicate the superiority of a specific vendor's technology. The following table highlights the characteristics of each solution:
| Implementation | Sequencing | Addressing | Aggregation | Channel Type | Product / Technology |
| A | Synchronous | Distribution | Channel | Web Service / SOAP | Java / Apache Axis |
| B | Asynchronous | Distribution | Correlation ID | Message Queue | C# / Microsoft MSMQ |
| C | Asynchronous | Auction | Correlation ID | Pub-Sub | TIBCO ActiveEnterprise |
The first implementation uses synchronous Web Services, implemented in Java and Apache Axis. The communication with each bank occurs over a separate HTTP channel which serves both as a request and reply channel. Therefore, the aggregation strategy is based on individual reply channels and does not require correlation. The second implementation uses an asynchronous approach with message queues. We implement it using Microsoft's MSMQ, but an implementation using JMS Queues or IBM WebSphere MQ could look very similar. The last implementation uses an Auction approach and leverages TIBCO's pub-sub infrastructure and the TIB/Integration Manager Process Manager tool. In option B and C, all reply messages arrive on a single channel and the implementations use Correlation Identifiers to associate reply messages to customer loan quote inquiries.
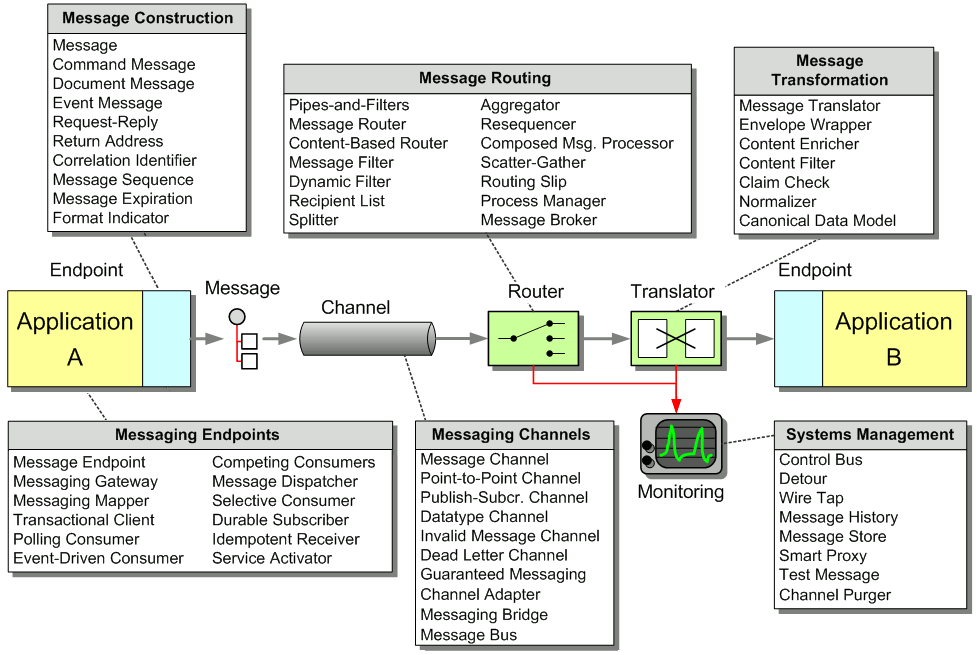
Integration Pattern Language