
November 30, 2004
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I like to work on and write about asynchronous messaging systems, service-oriented architectures, and all sorts of
enterprise computing and architecture topics. I am also an Enterprise Strategist at
AWS.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I like to work on and write about asynchronous messaging systems, service-oriented architectures, and all sorts of
enterprise computing and architecture topics. I am also an Enterprise Strategist at
AWS.
My blog posts related to IT strategy, enterprise architecture, digital transformation, and cloud have moved to a new home: ArchitectElevator.com.
There is a lot of debate about coupling these days. In fact, there is enough to be said about this topic that I'll leave most of it for a separate posting. Let it suffice to say that in my opinion coupling is a measure of dependency between systems. David Orchard has given us a nice definition of the ultimate loosely coupled solution by stating: "How do you make two systems loosely coupled? Don't connect them!" I believe one of the reasons we are having so many debates about coupling is due to the fact that we more commonly connect systems that were not necessarily designed to be connected in the first place. Naturally, the resulting debate is how much dependency and hence how much coupling to introduce between the systems.
Alas, there is rarely one right answer in software architecture and coupling is no exception. More coupling gives us efficiency and simplicity but can also introduce rigidity and brittleness. One example of generally more loosely coupled architectures are event-driven systems. These systems consist of a collection of individual processing elements that respond to incoming events. When a processing element receives an event message it perform its designated function and publishes one or more resulting events. These events can then be picked up by other processing nodes. A complete solution is created by composing the individual processing elements into a larger interconnected system (see figure).
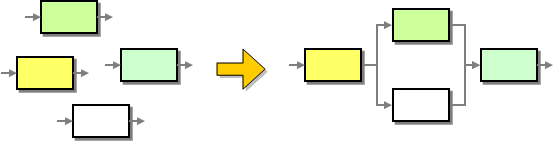
One of the advantages of composability is that the processing elements can be reused in various constellations because the elements do not make any direct assumptions about each other. This helps with reuse and provides flexibility to support future requirements. For example, it is quite easy to interject a new processing node between two existing nodes. But this flexibility also has a dark side (hear Darth Vader breathe). We built flexibility into the system by loosening the constraints on the system composition. This gives us the ability to recompose the system according to future needs. But this also means that the system has fewer means of detecting our mistakes. For example, we might have composed something that is perfectly valid according to the loosely coupled architecture but that does not actually do anything useful. For example, a processing element may listen for events that are never published. Or, the type of message on a channel might not match what the element expects.
As a result, integration testing is more critical than ever with loosely coupled, composable systems. We learned that lesson ourselves on a number of projects. The story goes kinda like this: Each component is thoroughly unit tested (for more on messaging and unit testing see Dependency Injection in Messaging Architectures) and produces the coveted green bar. However, the actual system exhibits fatal flaws, a popular one being a system that does plain nothing. Most of the time this happens because the individual components were improperly composed. We need to remind ourselves that in most systems 95% of all compositions don't actually do anything useful. However, as far as the flexible architecture is concerned, they are perfectly valid.
This implies that we need to think carefully about validating the composability as well as the actual composition of the individual processing elements. Neither one is a trivial task. Composability implies that individual processing elements do not make any undue assumptions about the actual composition. Often this cannot be validated by traditional testing because composability implies being able to use the component in unforeseen scenarios. Naturally, it is difficult to test explicitly for unforeseen scenarios. Instead, we often have to use code analysis or inspection to make any statements about composability. One of the biggest hindrances to composability are hidden assumptions. Hidden assumptions are often unavoidable but can also introduce a glut of problems. For example, if one component stores data in a central database that is read by another component, we introduced an "out of band" dependency between the two components. The main issue is that this dependency is not explicitly represented anywhere in the system and is often not detected until run-time.
Testing the actual composition of the individual elements is another important part of validating the system. This type of testing can be categorized as integration testing and sits in between unit testing and true functional (i.e. user) testing. This type of testing is important to validate that the chosen composition of the individual elements performs the desired functions. It typically does so by channeling test data into the system and comparing actual with expected results. Luckily, loosely coupled systems generally make it quite easy to inject test data so the mechanics of these test are quite simple. However, achieving proper test coverage can be challenging.
When creating these integration tests we need to be aware that with the introduction of composability we also introduced a new programming model into the application. The compositions follow the rules of a Pipes-and-Filters architecture, not an object-oriented architecture. This means that we deal with different constructs and rules. This requires us to rethink our approach to testing slightly.
Testing in the traditional sense will only perform part of the necessary validation. The reason for this is that in traditional programming models (for example, object-oriented programming) the compiler already validates a lot of the rules inherent in the programming model. For example, syntax errors, referencing an object before creating it etc. Because the composition layer follows our own rules, we often need to create our own validations. For example, is it valid to have loops? Is it valid to subscribe to an event that is never published? Is it valid to publish an event that no one subscribes to? Is it valid to have multiple subsystems that communicate amongst themselves but not between each other?
It is very useful to have means of inspecting the composition to execute these validation rules automatically. Because we can typically represent pipes-and-filters systems as a directed graph we can often draw on simple graph algorithms to perform these validations. The key is to consolidate information about event publishing and event subscription into a simple, central repository of sorts. That can preferably occur at design time or alternatively at run-time (for example, through a Control Bus). The importance of such validations is underlined by the fact that many architects consider the ability to perform automated analysis a key characteristic of an architectural style (for example, see Stylized Architecture, Design Patterns, and Objects ). Once the architectural style is expressed more formally, one can envision actual languages that can help express the desired constraints. This might in fact be useful in larger systems. Alternatively, we can translate the system structure into a more familiar syntax (for example, XML) and the use languages such as XPATH to execute the desired validations.
A less formal form of analysis is a visualization of the resulting system, for example as described in an earlier blog entry. In this case, the validation is only half automated because we use human beings to assess whether the composition is a good one or not. However, the system automatically preprocesses the information such that it is easily understood by human beings. This approach often turns out to be a quite reasonable compromise.
Building loosely coupled and composable systems have definite advantages. However, we have to keep in mind that such architectures introduce an additional layer, the composition layer, into the system. This layer has to be understood and tested separately as it often follows different architectural styles and design principles than the other layers.


 Gregor is an Enterprise Strategist with Amazon Web Services (AWS). He is a frequent
speaker on asynchronous messaging, IT strategy, and cloud. He (co-)authored several
books on architecture and architects.
Gregor is an Enterprise Strategist with Amazon Web Services (AWS). He is a frequent
speaker on asynchronous messaging, IT strategy, and cloud. He (co-)authored several
books on architecture and architects.