
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Find my posts on IT strategy, enterprise architecture, and digital transformation at ArchitectElevator.com.
I just got back from TheServerSide Symposium in Las Vegas. It was a great conference in a fun location. The highlight of the event was being bile-blogged and meeting Hani in person. My talk on Enterprise Integration Patterns also reminded me that the best way to really understand something is to explain it to someone else without resorting to armwaving (thanks, Hani!). After my presentation I felt that my explanation of the Correlation Identifier pattern might have included a more than necessary dose of armwaving so I am trying to make up for it here by drilling a bit deeper into this topic. Part of the credit definitely goes to Mark Hapner, Web Services Strategist for Sun, for insightful conversations during the vendor-sponsored lunch presentations.
One of the key differences between asynchronous messaging architectures and synchronous, call-stack based architectures is the fact that we have to work with a thinner safety net when building asynchronous solutions. For example, in synchronous applications the call stack keeps track of the return address and local variables so that we never have to worry about which method to return to and what the local state of that method was. Asynchronous architectures do not provide such mechanisms so that we have to track state and return addresses ourselves. A key mechanism to regaining local state is the notion of Correlation. Our book discusses correlation primarily within the context of the Correlation Identifier. The Correlation Identifier is introduced as addressing the following problem:
How does a requestor that has received a reply know which request this is the reply for?
The solution is to have the requestor add a Request ID to the request message, have the replier copy the Request ID to the Correlation ID field of the response message so that the requestor can correlate the reply message to the request message.
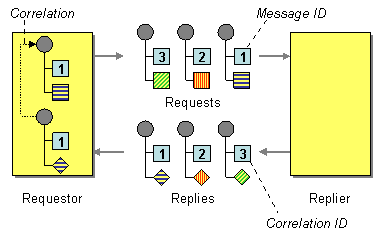
As far as the replier is concerned, the Correlation ID is an opaque data type and all it has to do is to copy the Request ID field from the request message to the Correlation ID field of the reply message. The key decision for the requestor is how to chose the Request ID. The picture seems to indicate that the Message ID is a suitable choice. In fact, many messaging systems do not provide a separate request ID field but assume that the Message ID field is used for this purpose. At first glance using the Message ID field seems convenient because most messaging systems automatically populate this field with a unique value for each message that is being sent, alleviating the requestor from having to generate a unique number.
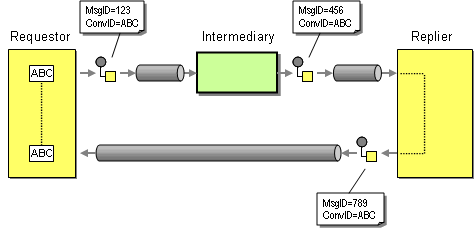
However, using the Message ID as the Request ID has at least one important limitation. It assumes that the requestor and the replier communicate directly with the exchange of a single message. To illustrate this point, let's see what happens when we insert and intermediary, such as a Message Router, between the requestor and the replier. The ability to insert intermediaries is one of the key benefits of the Pipes-and-Filters architectural style. Therefore, we are generally well advised to allow for the insertion of intermediaries without requiring changes to the existing components. In our case, inserting an intermediary causes an interesting problem (see picture).
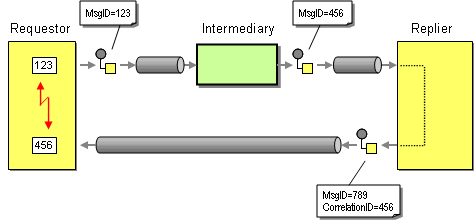
The intermediary consumes the original request message and sends a new message instance to the replier. Even though the message body of the new message created by the intermediary may be identical to the original request message, the new message is assigned its own unique Message ID by the messaging system. If the replier uses the Message ID as the Request ID and blindly copies it to the Correlation ID field of the reply message the requestor will not be able to correlate the incoming reply message to the original request message. The Request-Reply interaction is broken.
Luckily, there is another pattern that helps us solve the dilemma, the Smart Proxy. As the name suggest, a Smart Proxy proxies an existing service and brings some additional smarts into the game. The primary motivation for using a Smart Proxy is track message data between request and reply messages while allowing for the service consumer (the requestor) to specify a return address. However, as explained on page 560 of EIP the fact that the Smart Proxy keeps state between request and reply messages can be leveraged for other purposes as well. For example, the Smart Proxy can be used to reconstruct the Correlation Identifier for the reply message based on the message ID of the original request message (see picture below).
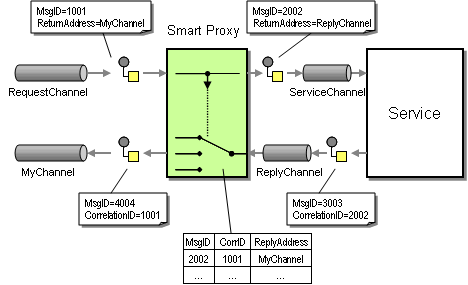
The Smart Proxy captures the message ID of the original request message and stores it. The Smart Proxy then uses the Correlation ID of the reply received from the service to look up that original message ID. It replaces the Correlation ID field in the reply message with the message ID of the request sent by the service consumer. As a result, the reply message from the Smart Proxy contains the Correlation ID expected by the service consumer.
This seems to solve out correlation dilemma quite nicely. The only constraint is that the Smart Proxy has to intercept both the request and the reply message. So far so good. But let's see what happens if the service we access is a composite service, i.e. a service that in turn accesses another service. If each service supports a smart proxy we get the following picture:
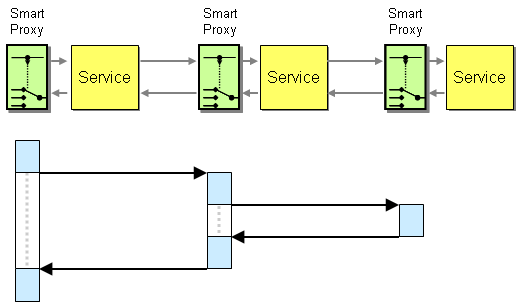
Each Smart Proxy holds the necessary state (for example, the return address and correlation ID) until it receives a response from the called sub-service(s). The bottom half of the picture illustrates how long each Smart Proxy has to keep this state. If that picture looks strangely familiar to you, I am not surprised -- it looks like a call stack. Each Smart Proxy keeps the Return Address and additional information while all sub-services execute just like a call stack maintains local variables and the return address. Instead of a Pipes-and-Filters message flow style we ended up building an artificial call stack on top of message channels. This is generally not a great idea. Keeping state for extended periods of time means that we have to persist the state to protect against failure. It also means that scalability in terms of message traffic may suffer because a high volume of messages may cause a large amount of state to be kept. Additionally, requiring reply messages to return the same path that the request messages were sent might mean unnecessary message traffic. Essentially, this solution exhibits many of the same limitations as a solution based on Remote Procedure Invocation. Overcoming these limitations was one of the main drivers for using Messaging so reverting back to the old synchronous paradigm does not sounds like a great idea.
So how can we avoid the unlucky "distributed call stack with messaging" architecture? It looks like using a message ID as a Correlation Identifier works well for a simple request-reply interaction but has limitations as soon as the flow of messages goes beyond a requestor and a replier. It seems like we need to look beyond just the simple request-reply interaction. When we look at message exchanges between systems in a broader context we realize that Request-Reply is just the most basic form of a Conversation between multiple systems. A conversation is the coordinated exchange of messages between two or more partners. The coordination is distributed as each participant in the conversation has a model of the conversation that relates to this participant's specific role in the conversation. For example, in a simple request-reply conversation the requestor knows to send a request message and expect a reply message while the replier (the service provider) knows to expect a request message and send a reply message in return. The topic of conversations has found a lot of interest in the Web services community. As one would expect, this interest has materialized in form of a WS?? four-letter-acronym, in this case the Web Services Conversation Language (WSCL) submitted by HP.
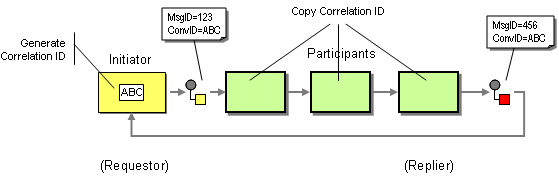
Before we dive deeper into the topic of modeling conversations and the relationship between conversations and orchestrations (a likely topic for a future rambling), let's get back to the correlation issue. We should have really named the Correlation Identifier, "Conversation Identifier". This would make it clear that the scope of this identifier spans an entire conversation, which may include intermediates or multiple services. Each message in the interchange would carry not only a message identifier but also a conversation identifier. The entity who initiates the conversation (in the Request-Reply example the requestor) picks a conversation ID while all intermediaries and repliers pass this ID along so that all messages belonging to the conversation carry a common conversation identifier. Separating this identifier from the message identifier nicely solves all the problems discussed above. as illustrated in the picture below:
We can even use the same Correlation ID field as the conversation identifier. The only difference is that we have to make the requestor populate the Correlation ID field and have the service provider copy the incoming Correlation ID field to the reply message Correlation ID field. Depending on the implementation the requestor could even use the Message ID value to set the Correlation ID field. Most implementations, however, do not allow this as the Message ID field is only populated after the message was sent.
Essentially, we now have redefined the roles of the entities. Instead of Requestor and Replier we now have two different roles:
The Conversation Originator has to populate the Correlation (Conversation) ID and all other participants have to pass this field along. The fact that the message ultimately is returned to the sender (the requestor) is purely coincidental in this model (see figure).
A Request-Reply interaction between a service consumer and a service provider is really just a simple example of a conversation between multiple participants. Therefore, to make the interaction between consumer and provider flexible and extensible the Correlation Identifier really should be used as Conversation Identifier. This implies that this identifier should be independent of any specific message identifier. Rather, it should be generated independently by the originator and propagated by any subsequent participant in the conversation.
Thanks to Rick Wise and James Strachan for insightful comments on this topic.
James Strachan alerted me that in the BPEL and BPMN world the term Correlation Identifier is used to identify the conversation, so calling it Conversation Identifier here might cause confusion. I readily admit that constraining the Correlation Identifier in our book to only the context of Request-Reply is inconsistent with the usage in the world of orchestration. The (narrowly defined) pattern in our book should probably have been called "Request Identifier". To minimize confusion, I am happy to use the term Correlation Identifier in both contexts, including conversations. This means we can use it synonymously with Conversation Identifier.
Share: Tweet
Follow:
Follow @ghohpe
![]() SUBSCRIBE TO FEED
SUBSCRIBE TO FEED
More On: MESSAGING PATTERNS CONVERSATIONS ALL RAMBLINGS


 Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.
Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.