|
This is a simple example that shows the power of publish/subscribe messaging, and explores the alternative designs available. It shows how multiple subscriber applications can all be informed of a single event by publishing the event just once, and considers alternative stratagies for how to communicate details of that event to the subscribers.
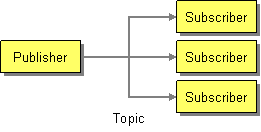
Publish/Subscribe using a JMS Topic
To understand how helpful a simple Publish-Subscribe Channel really is, we first need to consider what it is like to implement the Observer pattern in a distributed fashion, amongst multiple applications. Before we get to that, let's review the basics of Observer.
The Observer Pattern
The Observer pattern [GoF] documents a design through which an object can notify its dependents of a change, while keeping that object decoupled from its dependents so that the object works just fine no matter how many dependents it has, even none at all. Its participants are a Subject—the object announcing changes in its state—and Observers—objects interested in receiving notification of changes in the Subject. When a subject's state changes, it sends itself Notify(), whose implementation knows the list of observers and sends Update() to each of them. Some observers may not be interested in this state change, but those who are can find out what the new state is by sending GetState() to the subject. The subject must also implement Attach(Observer) and Detach(Observer) methods that the observers use to register interest.
Observer provides two ways to get the new state from the subject to the observer: the push model and the pull model. With the push model, the Update call to each observer contains the new state as a parameter. Thus interested observers can avoid having to call GetState(), but effort is wasted passing data to uninterested observers. The opposite approach is the pull model, where the subject sends basic notification and each observer requests the new state from the subject. Thus each observer can request the exact details it wants, even none at all, but the subject often has to serve multiple requests for the same data. The push model requires a single, one-way communication—the Subject pushes the data to an Observer as part of the update. The pull model requires three one-way communications—the Subject notifies an Observer, the Observer requests the current state from the Subject, and the Subject sends the current state to the Observer. As we'll see, the number of one-way communications affects both the design-time complexity and the runtime performance of the notification.
The easiest way to implement a Subject's Notify() method is with a single thread, but that can have undesirable performance implications. A single thread will update each observer one-at-a-time, in sequence; so those at the end of a long list of observers may need to wait a long time for updates. And a subject spending a long time updating all of its observers isn't accomplishing anything else. Even worse, an observer may well use its update thread to recact to the update, querying the subject for state and processing the new data; such observer work in the update thread makes the update process take even longer.
Thus the more sophisticated way to implement a Subject's Notify() method is to run each Update() call in its own thread. Then all observers can be updated concurrently, and whatever work each may do in its update thread does not delay the other observers or the subject. The downside is that implementing multithreading and handling thread-management issues is more complex.
Distributed Observer
The Observer pattern tends to assume that the Subject and its Observers all run in the same application. The pattern's design supports distribution, where the Observers run in a seperate memory space from the Subject and perhaps from each other, but the distribution takes work. The Update() and GetState() methods, as well as the Attach and Detach methods, must be made remotely accessible (see Remote Procedure Invocation). Because the Subject must be able to call each Observer and vise versa, each object must be running in some type of ORB environment that allows the objects it contains to be invoked remotely. And because the update details and state data will be passed between memory spaces, the applications must be able to serialize (e.g., marshall) the objects they are passing.
Thus implementing Observer in a distributed environment can get rather complex. Not only is a multi-threaded Observer somewhat difficult to implement, but then making methods remotely accessible—and invoking them remotely—adds more difficulty. The can be a lot of work just to notify some dependents of state changes.
Another problem is that a Remote Procedure Invocation only works when the source of the call, the target, and the network connecting them are all working properly. If a Subject announces a change and a remote Observer is not ready to process the notification or is disconnected from the network, the Observer looses the notification. While the Observer may work fine without the notification in some cases, in other cases the lost notification may cause the Observer to become out of sync with the Subject—the whole problem the Observer pattern is designed to prevent.
Distribution also favors the push model over the pull model. As discussed earlier, push requires a single one-way communication whereas pull requires three. When the distribution is implemented via RPC's (remote procedure calls), push requires one call (Update()) whereas pull requires at least two calls (Update() and GetState()). RPC's have more overhead than non-distributed method invocations, so the extra calls required by the push approach can quickly hurt performance.
Publish-Subscribe
A Publish-Subscribe Channel implements the Observer pattern, making the pattern much easier to use amongst distributed applications. The pattern is implemented in three steps:
- The messaging system administrator creates a Publish-Subscribe Channel. (This will be represented in Java applications as a JMS Topic.)
- The application acting as the Subject creates a TopicPublisher (a type of MessageProducer) to send messages on the channel.
- Each of the applications acting as an Observer (e.g., a dependent) creates a TopicSubscriber (a type of MessageConsumer) to receive messages on the channel. (This is analogous to calling the Attach(Observer) method in the Observer pattern.)
This establishes a connection between the subject and the observers through the channel. Now, whenever the subject has a change to announce, it does so by sending a message. The channel will ensure that each of the observers receives a copy of this message.
Here is a simple example of the code needed to announce the change:
import javax.jms.Connection;
import javax.jms.ConnectionFactory;
import javax.jms.Destination;
import javax.jms.JMSException;
import javax.jms.MessageProducer;
import javax.jms.Session;
import javax.jms.TextMessage;
import javax.naming.NamingException;
public class SubjectGateway {
public static final String UPDATE_TOPIC_NAME = "jms/Update";
private Connection connection;
private Session session;
private MessageProducer updateProducer;
protected SubjectGateway() {
super();
}
public static SubjectGateway newGateway() throws JMSException, NamingException {
SubjectGateway gateway = new SubjectGateway();
gateway.initialize();
return gateway;
}
protected void initialize() throws JMSException, NamingException {
ConnectionFactory connectionFactory = JndiUtil.getQueueConnectionFactory();
connection = connectionFactory.createConnection();
session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Destination updateTopic = JndiUtil.getDestination(UPDATE_TOPIC_NAME);
updateProducer = session.createProducer(updateTopic);
connection.start();
}
public void notify(String state) throws JMSException {
TextMessage message = session.createTextMessage(state);
updateProducer.send(message);
}
public void release() throws JMSException {
if (connection != null) {
connection.stop();
connection.close();
}
}
}
SubjectGateway is a Messaging Gateway between the Subject (not shown) and the messaging system. The subject creates the gateway and then uses it to broadcast notifications. Essentially, the subject's Notify() method is implemented to call SubjectGateway.notify(String). The gateway then announces the change by sending a message on the update channel.
And here is an example of the code needed to receive the change notification:
import javax.jms.Connection;
import javax.jms.ConnectionFactory;
import javax.jms.Destination;
import javax.jms.JMSException;
import javax.jms.Message;
import javax.jms.MessageConsumer;
import javax.jms.MessageListener;
import javax.jms.Session;
import javax.jms.TextMessage;
import javax.naming.NamingException;
public class ObserverGateway implements MessageListener {
public static final String UPDATE_TOPIC_NAME = "jms/Update";
private Observer observer;
private Connection connection;
private MessageConsumer updateConsumer;
protected ObserverGateway() {
super();
}
public static ObserverGateway newGateway(Observer observer)
throws JMSException, NamingException {
ObserverGateway gateway = new ObserverGateway();
gateway.initialize(observer);
return gateway;
}
protected void initialize(Observer observer) throws JMSException, NamingException {
this.observer = observer;
ConnectionFactory connectionFactory = JndiUtil.getQueueConnectionFactory();
connection = connectionFactory.createConnection();
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Destination updateTopic = JndiUtil.getDestination(UPDATE_TOPIC_NAME);
updateConsumer = session.createConsumer(updateTopic);
updateConsumer.setMessageListener(this);
}
public void onMessage(Message message) {
try {
TextMessage textMsg = (TextMessage) message; // assume cast always works
String newState = textMsg.getText();
update(newState);
} catch (JMSException e) {
e.printStackTrace();
}
}
public void attach() throws JMSException {
connection.start();
}
public void detach() throws JMSException {
if (connection != null) {
connection.stop();
connection.close();
}
}
private void update(String newState) throws JMSException {
observer.update(newState);
}
}
ObserverGateway is another Messaging Gateway, this time between the Observer (not shown) and the messaging system. The observer creates the gateway, then uses attach() to start the Connection (which is analogous to calling the Attach(Observer) method in the Observer pattern). The gateway is an Event-Driven Consumer, so it implements the MessageListener interface, which requires the onMessage method. In this way, when an update is received, the gateway processes the message to get the new state, and calls is own update(String) method which calls the corresponding message in the observer.
These two classes implement the push model version of Observer. With the notification message sent by SubjectGateway.notify(String), the existance of the message tells the Observer that a change has occurred, but it is the contents of the message that tell the Observer what the Subject's new state is. The new state is being pushed from the Subject to the Observer. As we'll see later, there's another way to implement all this using the pull model.
Comparisons
For distributed notification between applications, the Publish-Subscribe (e.g., messaging) approach has several advantages over the traditional, synchronous (e.g., RPC) approach of implementing Observer:
- Simplifies Notification — The Subject's implementation of Notify() becomes incredibly simple; the code just has to send a message on a channel. Likewise, Observer.Update() just has to receive a message.
- Simplifies Attach/Detach — Rather than attach to and detach from the Subject, an Observer needs to subscribe to and unsubscribe from the channel. The Subject does not need to implement Attach(Observer) or Detach(Observer) (although the Observer may implement these methods to encapsulate the subscribe and unsubscribe behavior).
- Simplifies Concurrent Threading — The Subject only needs one thread to update all Observers concurrently—the channel delivers the notification message to the Observers concurrently—and each Observer handles the update in its own thread. This simplifies the Subject's implementation, and because each Observer uses its own thread, what one does in its update thread does not affect the others.
- Simplifies Remote Access — Niether the Subject nor the Observers have to implement any remote methods, nor do they need to run in an ORB. They just need to access the messaging system and it handles the distribution.
- Increases Reliability — Because the channel uses messaging, notifications will be queued until the Observer can process them, which also enables the Observer to throttle the notifications. If an Observer wants to receive notifications that are sent while that Observer is disconnected, it should make itself a Durable Subscriber.
One issue that the Publish-Subscribe approach does not change is serialization. Whether Observer is implemented through RPC or messaging, state data is being distributed from the Subject's memory space to each Observer's memory space, so the data has to be serialized (e.g., marshalled). This behavior has to be implemented for either approach.
If the Publish-Subscribe approach has a downside, it's that the approach requires messaging, which means that the Subject and Observer applications must have access to a shared messaging system and must be implemented as clients of that messaging system. Still, making applications into messaging clients is no more difficult, and probably easier, than using the RPC approach.
Push and Pull Models
Another potential downside of the Publish-Subscribe approach is that the pull model is more complex than the push model. As discussed earlier, the pull model requires more discussion back and forth than the push model. When the discussion is amongst distributed applications, the extra communication can significantly hurt performance.
The communication is more complex with messaging than with RPC. In both cases, Update() is a one-way communication, either an RPC that returns void or a single Event Message from the Subject to the Observer. The tricker part is when an Observer needs to query the Subject's state; GetState() is a two-way communication, either a single RPC that requests the state and returns it, or a Request-Reply—a pair of messages where a Command Message requests the state and a separate Document Message returns it.
What makes Request-Reply more difficult is not just that it requires a pair of messages, but that it requires a pair of channels to transmit those messages. One channel, the get-state-request channel, goes from an Observer to the Subject; an Observer sends the state request on that channel. The other channel, the get-state-reply channel, goes from the Subject back to the Observer; the Subject sends the state reply on that channel. All of the Observers can share the same request channel, but they will probably each need their own reply channel. Each Observer needs to receive not just any response, but the particular response for its specific request, and the easiest way to ensure this is for each Observer to have its own reply channel. (An alternative is to use a single reply channel and use Correlation Identifiers to figure out which reply goes to which observer, but a separate channel per observer is a lot easier to implement.)
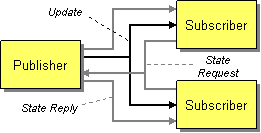
Publish/Subscribe using the Pull Model
A reply channel for each Observer can lead to an explosion of channels. Such a large number of channels may be managable, but the messaging system administrator does not know how many static channels to create when the number of Observers needing to use these channels changes dynamicly at runtime. Even if there are enough channels for all of the Observers, how does each Observer know which channel to use?
JMS has a feature, TemporaryQueue, specifically for this purpose. [Hapner, p.60] (Also see the discussion in Request-Reply.) An Observer can create a temporary queue, just for its own use, specify that as the Return Address in its request, and wait for the reply on that queue. Creating new queues frequently can be inefficient, depending on your messaging system's implementation, and temporary queues cannot be persistent (for use with Guaranteed Delivery). However, if you don't want to use the push model, you can implement the pull model using temporary queues.
These two classes show how to implement the gateways using the pull model.
import javax.jms.Connection;
import javax.jms.ConnectionFactory;
import javax.jms.Destination;
import javax.jms.JMSException;
import javax.jms.Message;
import javax.jms.MessageConsumer;
import javax.jms.MessageListener;
import javax.jms.MessageProducer;
import javax.jms.Session;
import javax.jms.TextMessage;
import javax.naming.NamingException;
public class PullSubjectGateway {
public static final String UPDATE_TOPIC_NAME = "jms/Update";
private PullSubject subject;
private Connection connection;
private Session session;
private MessageProducer updateProducer;
protected PullSubjectGateway() {
super();
}
public static PullSubjectGateway newGateway(PullSubject subject)
throws JMSException, NamingException {
PullSubjectGateway gateway = new PullSubjectGateway();
gateway.initialize(subject);
return gateway;
}
protected void initialize(PullSubject subject) throws JMSException, NamingException {
this.subject = subject;
ConnectionFactory connectionFactory = JndiUtil.getQueueConnectionFactory();
connection = connectionFactory.createConnection();
session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Destination updateTopic = JndiUtil.getDestination(UPDATE_TOPIC_NAME);
updateProducer = session.createProducer(updateTopic);
new Thread(new GetStateReplier()).start();
connection.start();
}
public void notifyNoState() throws JMSException {
TextMessage message = session.createTextMessage();
updateProducer.send(message);
}
public void release() throws JMSException {
if (connection != null) {
connection.stop();
connection.close();
}
}
private class GetStateReplier implements Runnable, MessageListener {
public static final String GET_STATE_QUEUE_NAME = "jms/GetState";
private Session session;
private MessageConsumer requestConsumer;
public void run() {
try {
session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Destination getStateQueue = JndiUtil.getDestination(GET_STATE_QUEUE_NAME);
requestConsumer = session.createConsumer(getStateQueue);
requestConsumer.setMessageListener(this);
} catch (Exception e) {
e.printStackTrace();
}
}
public void onMessage(Message message) {
try {
Destination replyQueue = message.getJMSReplyTo();
MessageProducer replyProducer = session.createProducer(replyQueue);
Message replyMessage = session.createTextMessage(subject.getState());
replyProducer.send(replyMessage);
} catch (JMSException e) {
e.printStackTrace();
}
}
}
}
PullSubjectGateway is very similar to SubjectGateway. The pull version now has a reference to its subject so that the gateway can query the subject for its state when requested by an observer. notify(String) has now become notifyNoState(), because the pull model simply sends out notification without including any state (and because Java already uses the method name notify()).
The big addition for the pull model is GetStateReplier, an inner class that implements Runnable so that it can run in its own thread. It is also a MessageListener, which makes it an Event-Driven Consumer. Its onMessage method reads requests from the GetState queue and sends replies containing the subject's state to the queue specified by the request. In this way, when an observer makes a GetState() request, the gateway sends a reply (see Request-Reply).
import javax.jms.Destination;
import javax.jms.JMSException;
import javax.jms.Message;
import javax.jms.MessageConsumer;
import javax.jms.MessageListener;
import javax.jms.Queue;
import javax.jms.QueueConnection;
import javax.jms.QueueConnectionFactory;
import javax.jms.QueueRequestor;
import javax.jms.QueueSession;
import javax.jms.Session;
import javax.jms.TextMessage;
import javax.naming.NamingException;
public class PullObserverGateway implements MessageListener {
public static final String UPDATE_TOPIC_NAME = "jms/Update";
public static final String GET_STATE_QUEUE_NAME = "jms/GetState";
private PullObserver observer;
private QueueConnection connection;
private QueueSession session;
private MessageConsumer updateConsumer;
private QueueRequestor getStateRequestor;
protected PullObserverGateway() {
super();
}
public static PullObserverGateway newGateway(PullObserver observer)
throws JMSException, NamingException {
PullObserverGateway gateway = new PullObserverGateway();
gateway.initialize(observer);
return gateway;
}
protected void initialize(PullObserver observer) throws JMSException, NamingException {
this.observer = observer;
QueueConnectionFactory connectionFactory = JndiUtil.getQueueConnectionFactory();
connection = connectionFactory.createQueueConnection();
session = connection.createQueueSession(false, Session.AUTO_ACKNOWLEDGE);
Destination updateTopic = JndiUtil.getDestination(UPDATE_TOPIC_NAME);
updateConsumer = session.createConsumer(updateTopic);
updateConsumer.setMessageListener(this);
Queue getStateQueue = (Queue) JndiUtil.getDestination(GET_STATE_QUEUE_NAME);
getStateRequestor = new QueueRequestor(session, getStateQueue);
}
public void onMessage(Message message) {
try {
// message's contents are empty
updateNoState();
} catch (JMSException e) {
e.printStackTrace();
}
}
public void attach() throws JMSException {
connection.start();
}
public void detach() throws JMSException {
if (connection != null) {
connection.stop();
connection.close();
}
}
private void updateNoState() throws JMSException {
TextMessage getStateRequestMessage = session.createTextMessage();
Message getStateReplyMessage = getStateRequestor.request(getStateRequestMessage);
TextMessage textMsg = (TextMessage) getStateReplyMessage; // assume cast always works
String newState = textMsg.getText();
observer.update(newState);
}
}
Again, PullObserverGateway is similar to ObserverGateway, but with some more code to implement the pull model. In initialize, it not only sets up updateConsumer to listen for updates, but also sets up getStateRequestor to send GetState() requests. (getStateRequestor is a QueueRequestor; see Request-Reply.) In the pull version, the gateway's onMessage code ignores the message's contents because the message is empty. The message's existance tells the observer that the subject has changed, but does not tell the observer what the subject's new state is. So all there is to do is call updateNoState() (named similarly to notifyNoState()).
The difference for the Observer between the push and pull models becomes apparent in the implementation of updateNoState() vs. update(String). Whereas the push version gets the new state as a parameter and just has to update the observer, the pull version must go get the new state before it can update the observer. To get the new state, it uses the getStateRequestor to send a request and get the reply. The reply contains the subject's new state, which the gateway uses to update the observer. (Note that in this simple implementation, the gateway is single-threaded, so while it is sending the get-state request and waiting for the reply, it is not processing any more updates. Thus if the request or reply messages take a really long time to transmit, the gateway will be stuck waiting and any more updates that occur will simply queue up.)
So as you can see, the pull model is more complex than the push model. It requires more channels (including a temporary one for every observer), it requires more messages (three messages per update per interested observer instead of one message for all observers), the subject and observer classes require more code to manage the additional messaging, and the objects at runtime require more threads to execute the additional messaging. If all of this is acceptable in your application, then the pull model is a viable approach. However, if in doubt, you should probably start with the push model because it is simpler.
Channel Design
So far, we've considered one Subject with one piece of state notifying its Observers. Using the push model, this requires one Publish-Subscribe Channel for communicating changes in the Subject's state to the Observers.
Real enterprise applications are much more complex. An application can contain lots of Subjects that need to announce changes. Each Subject often contains several different pieces of state, called aspects, that can change independently. A single Observer might be interested in several different aspects in several different Subjects, where the Subjects are not only multiple instances of the same class, but may well be instances of different classes.
So update semantics in sophsticated applications can quickly become complex. The Observer pattern address this as implementation issues like "Observing more than one subject" and "Specifying modifications of interest explicitly." Also, the SASE (Self-Addresses Stamped Envelope) pattern describes a combination of the Observer and Command patterns whereby an observer specifies the command a subject should send it when a certain change occurs. [Alpert, pp.312-314]
Without getting too deep into the issues of making sure observers only receive the updates they need, let's consider the implications for messaging, namely: How many channels will we need?
Let's first consider a simple case. An enterprise may have several different applications responsible for storing a customer's contact information, such as a mailing address. When a customer's address is updated in one of these applications, the application should notify other applications that may need this new information as well. Meanwhile, there may be several applications that need to know when an address changes, so they would like to register to receive notification.
This is a simple problem to solve. All that is needed is a single Publish-Subscribe Channel for announcing address changes. Each application that can change an address then also has the responsibility to announce that change by publishing a message on the channel. Each application that wishes to receive notification subscribes to the channel. A particular change message might look like this:
<AddressChange customer_id="12345"> <OldAddress> <Street>123 Wall Street</Street> <City>New York</City> <State>NY</State> <Zip>10005</Zip> </OldAddress> <NewAddress> <Street>321 Sunset Blvd</Street> <City>Los Angeles</City> <State>CA</State> <Zip>90012</Zip> </NewAddress> </AddressChange>
Now let's consider another problem. The enterprise may also have applications that need to announce when they are out of a product, and others that need to receive these notifications so that they can reorder the product. This is just a different example of the last problem, and is solved the same way by using a Publish-Subscribe Channel to make out-of-product announcements. One of these messages might look like this:
<OutOfProduct> <ProductID>12345</ProductID> <StoreID>67890</StoreID> <QuantityRequested>100</QuantityRequested> </OutOfProduct>
But this leads us to wonder: Can we use the same channel for customer address changes and for out-of-product announcements? Probably not. First, Datatype Channel tells us that all of the messages on a channel must be of the same type, which in this case means that they must all conform to the same XML schema. <AddressChange> is obviously a very different element type from <OutOfProduct>, so they should not be sent on the same channel. Perhaps the data formats could be reworked so that both message types fit the same schema and receivers could tell which messages were for addresses and which were for products. But then the problem is that the applications interested in address changes are probablty not the same ones interested in product updates, so if the messages use the same channel, an application will frequently receive notifications it's not interested in. Thus is makes sense to have two separate address change and product update channels.
Now consider a third case where a customer's credit rating could change. The message might look like this:
<CreditRatingChange customer_id="12345"> <OldRating>AAA</OldRating> <NewRating>BBB</NewRating> </CreditRatingChange>
Like the case with product notifications, it might be tempting to solve the problem with a new credit-rating-changed channel (in addition to the address-changed and out-of-product channels). This would keep the credit rating changes separate from the address changes, and would allow dependents to only register for the type of changes they're interested in.
The problem with this approach is that it can lead to a channel explosion. Consider all the pieces of data that may be known about a customer: name; contacts (address, phone number, e-mail) for mailing, shipping, and billing; credit rating; service level; standard discount; etc. Each time any one of these aspects changes, other applications may need to know about it. Creating a channel for each can lead to lots of channels.
Large numbers of channels may tax the messaging system. Numerous channels with little traffic on each can waste resources and make load difficult to distribute. Or, numerous channels with lots of little messages can add to messaging overhead. Dependents can become confused as to which of a large number of channels to subscribe to. Multiple channels require multiple senders and receivers, perhaps leading to lots of threads checking lots of channels that are usually empty. So creating yet more channels may not be such a good idea.
What may work better is to send both the address-changed and credit-rating-changed messages on the same channel, since they both concern changes to the customer and an application interested in one kind of change may be interested in the others as well. Yet a separate out-of-product channel is still a good idea since applications interested in customers may not be interested in products and vise versa.
The address-changed and credit-rating-changed messages have different formats, yet Datatype Channel tells us that to be on the same channel, the messages must have the same format. With XML, this means that all of the messages must have the same root element type, but perhaps can have different optional nested elements. So unified customer-changed messages might look like this:
<CustomerChange customer_id="12345"> <AddressChange> <OldAddress> <Street>123 Wall Street</Street> <City>New York</City> <State>NY</State> <Zip>10005</Zip> </OldAddress> <NewAddress> <Street>321 Sunset Blvd</Street> <City>Los Angeles</City> <State>CA</State> <Zip>90012</Zip> </NewAddress> </AddressChange> </CustomerChange>
<CustomerChange customer_id="12345"> <CreditRatingChange> <OldRating>AAA</OldRating> <NewRating>BBB</NewRating> </CreditRatingChange> </CustomerChange>
There may still be the problem that shipping applications interested in address changes are not interested in credit rating changes, and billing applications are interested in the opposite. These applications can use Selective Consumers to get only the messages of interest. If selective consumers prove to be complicated and a messaging system can easily support more channels, then perhaps separate channels would be better after all.
As with may issues in enterprise architecture and design, there are no simple answers and lots of tradeoffs. With Publish-Subscribe Channel (as with any message channel), the goal is to help ensure that the observers only receive the notifications they need, without an explosion of separate channels and without taxing the typical observer with lots of threads running lots of consumers monitoring lots of channels.
Conclusions
This chapter shows that Publish-Subscribe Channels are an implementation of the Observer pattern that make the pattern much easier to use in distributed environments. When a channel is used, Subject.Notify() and Observer.Update() become much simpler because all they have to do is send and receive messages. The messaging system takes care of distribution and concurrency while making the remote notification more reliable. The push model is simpler and often more efficient than the pull model, especially for distributed notification, especially with messaging; yet the pull model can also be implemented using messaging. In complex applications where lots of data can change, it may be tempting to create a channel for every different thing that can change, but it's often more practical to use the same channel to trasmit similar notifications going to the same observers. Even if your applications don't need messaging for anything else, if they need to notify each other of changes, it may well be worth using Messaging just so you can take advantage of Publish-Subscribe Channels.
Integration Pattern Language